
ETL Jobs
ETL Jobs enables the user to run python, pyspark and drag-and-drop built codes in order to work on the user’s datasets. By using this action, user can perform any operation on the datasets.
Create an ETL Job
Click on 'ETL' and choose 'Jobs' from the dropdown list in order to access and create jobs. The Jobs can be created using the '+' icon on the top Right of page under section.
Job creation page will be displayed with the following fields:
Name: The name by which the user wants to create the job. The name must be unique across the amorphic platform.
Description: A brief description about the job created.
Job Type: The user needs to specify and describe the type of job registration whether it is a Spark Job, Python Job or a Morph (Drag-and-Drop ETL Job Builder) Job. Please refer Morph ETL Jobs Documentation for details.
Bookmark: The user needs to specify whether to enable/disable/pause a job bookmark. If job bookmark is enabled then the user needs to add a parameter transformation_ctx to their Glue dynamic frame so glue can store the state information.
Max Concurrent Runs: This specifies the maximum number of concurrent runs allowed for the job
Max Retries: The specified number will be the maximum number of times the job will be retried if it fails
Allocated Capacity: Allocated capacity is the number of AWS Glue data processing units to allocated to the job (This parameter is available for both Spark & Python Job) OR
- Worker Type: The type of predefined worker that is allocated when a job runs. User can select one of Standard, G.1X, or G.2X. For more info on worker type please refer AWS Documentation (This parameter is available for only Spark Job) AND
- Number Of Workers: The number of workers of a defined workerType that are allocated when a job runs. The maximum number of workers user can define are 299 for G.1X , and 149 for G.2X (This parameter is available for only Spark Job)
Timeout: Maximum time that a job can run can consume resources before it is terminated. Default timeout is 48 hrs
Notify Delay after: After a job run starts, the number of minutes to wait before sending a job run delay notification
Datasets Write Access: User can select datasets with the write access required for the job
Datasets Read Access: User can select datasets with the read access required for the job
Domains Write Access: User can select domains with the write access required for the job. User will have write access to all the datasets (existing and newly created if any) under the selected domains.
Domains Read Access: User can select domains with the read access required for the job. User will have read access to all the datasets (existing and newly created if any) under the selected domains.
Parameters Access: User accessible parameters from the parameters store will be displayed. User can use these parameters in the ETL script.
Shared Libraries: User accessible shared libraries will be displayed. User can use these libraries in the ETL script for dependency management.
Job Parameter: User can specify arguments that job execution script consumes, as well as arguments that AWS Glue consumes. However, adding/modifying ["--extra-py-files", "--extra-jars", "--TempDir", "--class", "--job-language", "--workflow_json_path", "--job-bookmark-option"] arguments are restricted to user for an ETL job.
Network Configuration: There are five types of network configurations i.e. Public, App-Public-1, App-Private-1, App-Public-2 and App-Private-2.
- Public, App-Public-1 and App-Public-2 jobs have direct access to internet.
- App-Public-1 & App-Public-2 deploys jobs in public subnet of Amorphic application whereas Public job is deployed in AWS Default VPC subnets.
- App-Private-1 & App-Private-2 jobs doesn't have direct access to internet. It is deployed in private subnet of Amorphic application VPC.
Keywords: Keywords for the etl job. Keywords are indexed and searchable within the application. Please choose keywords which are meaningful to you and others. You can use these to flag related jobs with the same keywords so that you can easily find them later.
Glue Version: Based on the selected Job Type, user may select respective Glue Version to use while provisioning/updating an ETL job. Currently Glue Version(s) 1.0, 2.0 & 3.0 is supported for Spark jobs & only 1.0 for Python Shell jobs. For Morph job, user is not required to select Glue Version.
NoteAs per latest release, there are three major changes done with respect to Glue & Python Version :-
- Glue Version 0.9 is deprecated for both Python Shell & Spark jobs.
- Python Version 2.7 is deprecated for Python Shell & Spark jobs irrespective of Glue Version selected.
- Glue Version 3.0 is introduced for Spark jobs. There is one important thing that needs to be kept in mind when user is working with Glue 3.0. Since Glue 3.0 and Glue 2.0 are built on different Spark versions, Glue 3.0 is unable to support DataFrame properly when reading/writing data to a dataset. Hence user must use Spark DynamicFrame instead of DataFrame in job script to resolve Access Denied issues while reading/writing data to dataset via Spark job.
NoteUsers won't be allowed to create an ETL job with the above deprecated versions of Glue as well as Python from the Amorphic console through API or UI. Users won't be able to update attributes(Eg. Description, AllocatedCapacity, etc.) as well as external job libraries of existing jobs with deprecated Glue/Python versions. However they will still be allowed to execute existing jobs. . Users will need to manually update the Glue/Python version of ETL job(existing job with deprecated version) to newer supported versions, if any modification is required in existing jobs. It will soon become mandatory to do so.
Notification settings has been moved to Settings page and using that user can choose the type of notification setting for the ETL job. Please check the documentation on Notification settings
Once the Job metadata is created, Page is navigated to 'Edit script' page where the user is required to provide the script for the ETL Job and publish the Job.
To write a file to a dataset through ETL Jobs
If user wants to write to LZ bucket and follow the LZ process with validations then follow the below file name convention:
<Domain>/<DatasetName>/<partitions_if_any>/upload_date=<epoch>/<UserId>/<FileType>/<FileName>
ex: TEST/ETL_Dataset/part=abc/upload_date=123123123/apollo/csv/test_file.csv
If user want to write directly to DLZ bucket and skip the LZ process then user should set Skip LZ (Validation) Process to True for the destination dataset and follow the below file name convention:
<Domain>/<DatasetName>/<partitions_if_any>/upload_date=<epoch>/<UserId>_<DatasetId>_<epoch>_<FileNameWithExtension>
ex: TEST/ETL_Dataset/part=abc/upload_date=123123123/apollo_1234-4567-8910abcd11_123123123_test_file.csv
View Job
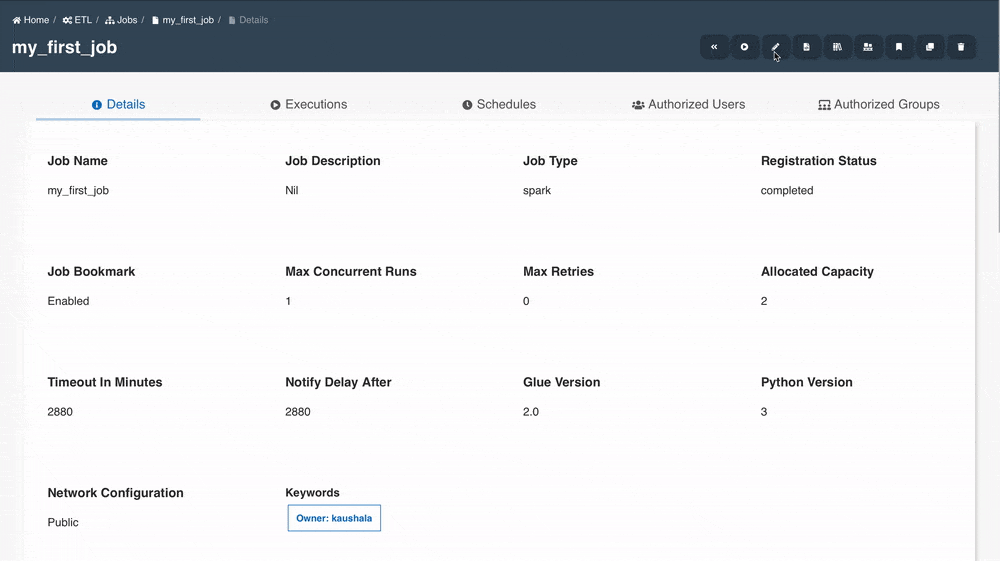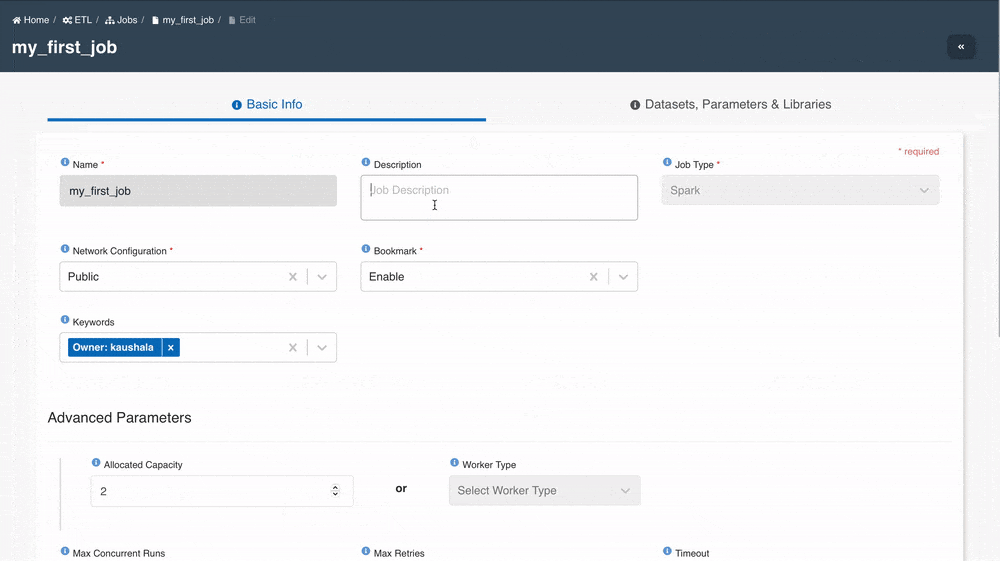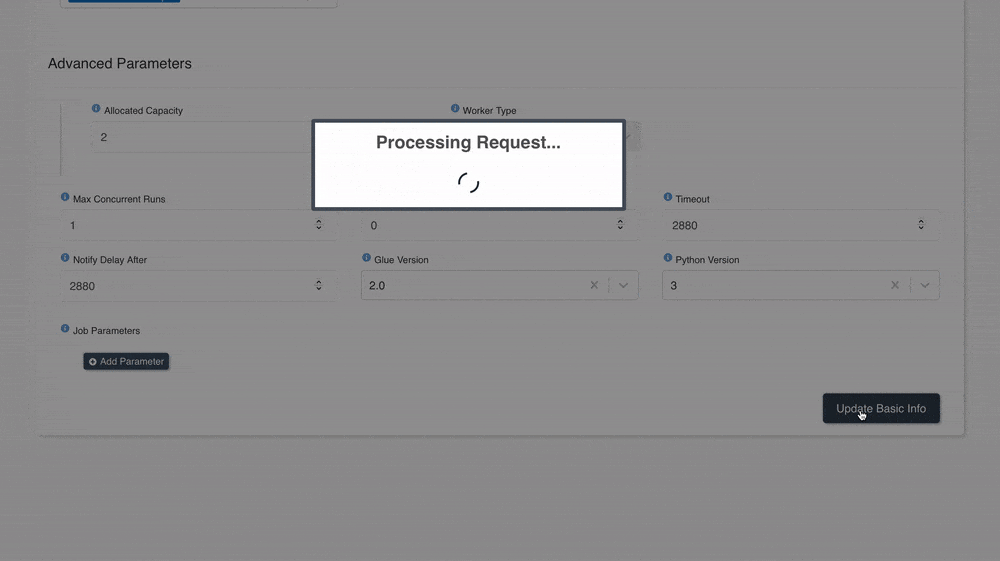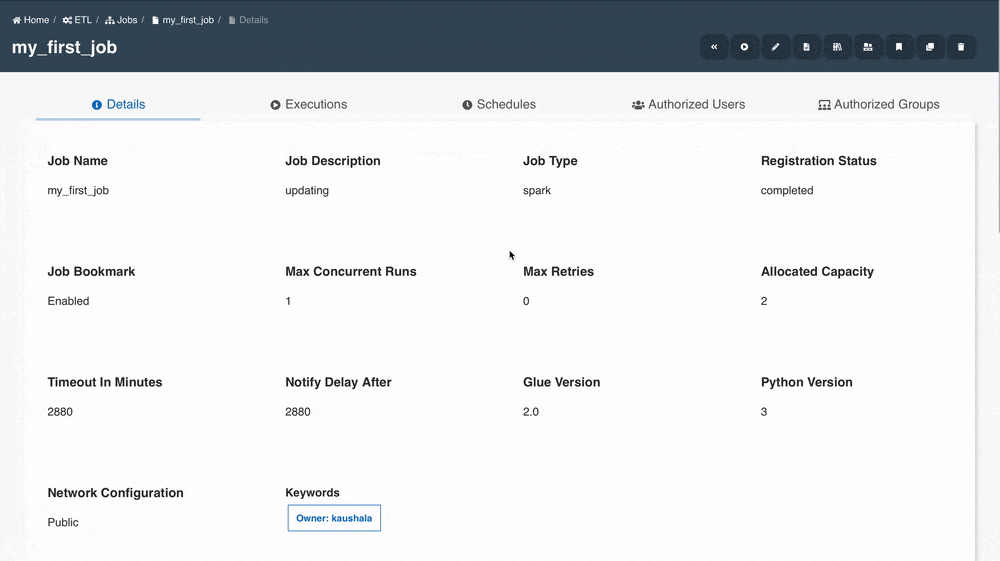
Job details page should be displayed with all the details specified and also with the default values for the unspecified fields (if applicable).

Edit Job
Job details can be edited using the 'Edit Job Details' button and changes will be reflected in the details page immediately.
The Edit Job page is divided into two sections:
Basic Info: User can use this section to update all the basic details of ETL job.
Datasets, Domains, Parameters & Libraries: User can use this section to update resources which requires access permissions.
Edit Script
Job script can be edited/updated anytime using the 'Edit Script' button. Once the script is loaded in the script editor, Turn off the read mode and edit the script accordingly. Click on 'Save & Exit' button to save the final changes.
The following picture depicts the script editor:
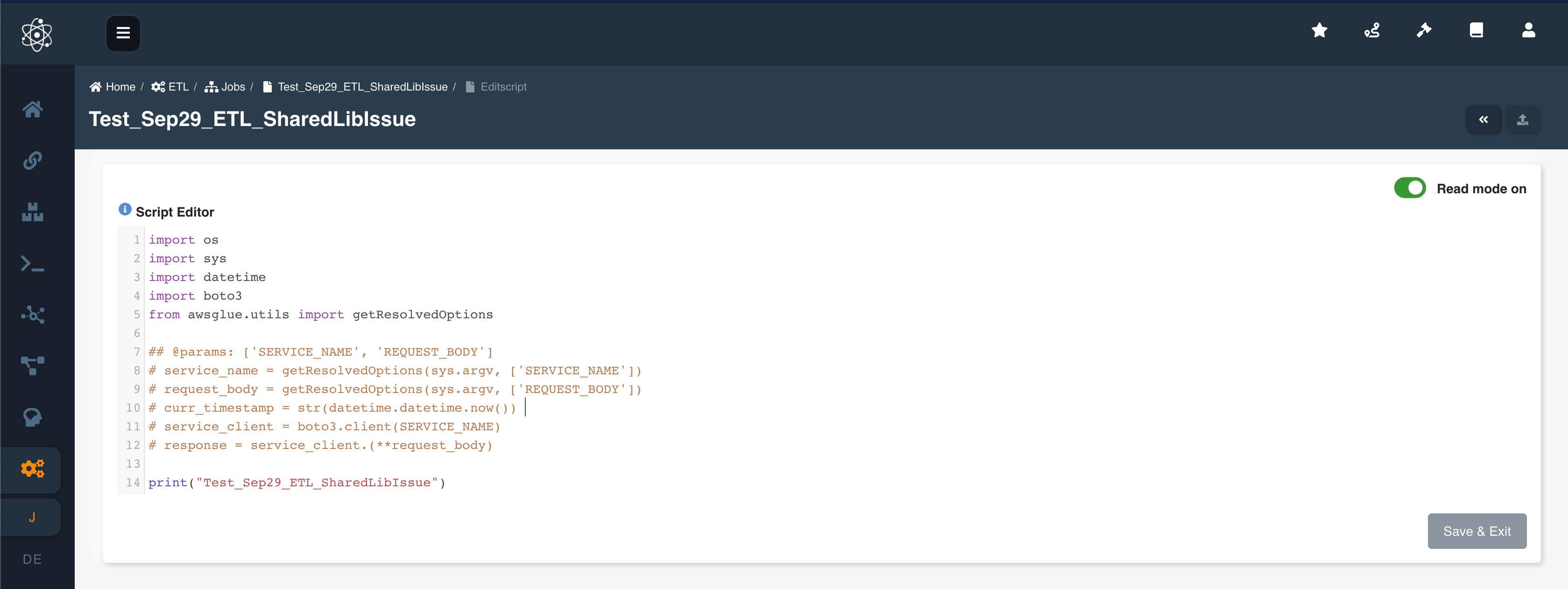
User can also load the script from a python file using the 'Load Script' (upload) button on the top right side of the script editor.
Update External Libraries
User can upload external libraries to ETL job using the 'Update External Libs' button on the top right side of the details page. Click on the 'Upload New Libs' button & then Click on 'Select Files' & 'Upload File(s)' button to upload one or more library file(s).
The following pictures depicts the external libraries popups:


Uploaded library file(s) will be displayed in the details page immediately.

User can remove the external libraries from the ETL job by selecting the libraries and clicking on the 'Remove selected libraries' button. User can also download the external libraries by clicking on 'Download file' button displayed on the right of each uploaded library path.
Update Extra Resource Access
To provide parameter or shared libraries or dataset access to a job in large number, use the documentation on How to provide large number of resources access to an ETL Entity in Amorphic
Run Job
To execute the ETL Job, click on the Run Job (play icon) button on the top right side of the page. Once a job run is executed, refresh the execution status tab using the Refresh button and check the status.


Once the job execution is completed, Email notification will be sent based on the notification setting and job execution status.
User can stop/cancel the job execution if the execution is in running state.
User might see the below error if the ETL job is executed immediately after creating it.
Failed to execute with exception “Role should be given assume role permissions for Glue Service”
In this case, User can try executing it again.
The following picture depicts how to stop the ETL job execution:

Job executions
Once a ETL job is executed, the executions will be displayed in the 'Executions' tab. All executions of the ETL job will be displayed by default.
If user wants to filter the executions based on the time of execution then executions can be filtered by using the 'From Date', 'To Date' calendar fields in the 'Executions' tab.
Select the range of time of executions and click the 'Apply' button to retrieve the executions based on the specified time frame. User can view all the ETL job executions anytime using either the 'Refresh' button or the time frame specifying 'To Date' as current time.
The following picture depicts how to filter the ETL job executions and also reset to view all executions:

If the Job has Max Retries value then the job will display all the executions including the retry attempts. Attempt number will be displayed beside the run id.
The following picture depicts the retry attempts of the ETL execution:

The job executions also contain executions that have been triggered via etl job schedules, etl nodes in workflows and workflow schedules. User can also check the corresponding trigger source for the execution entry.
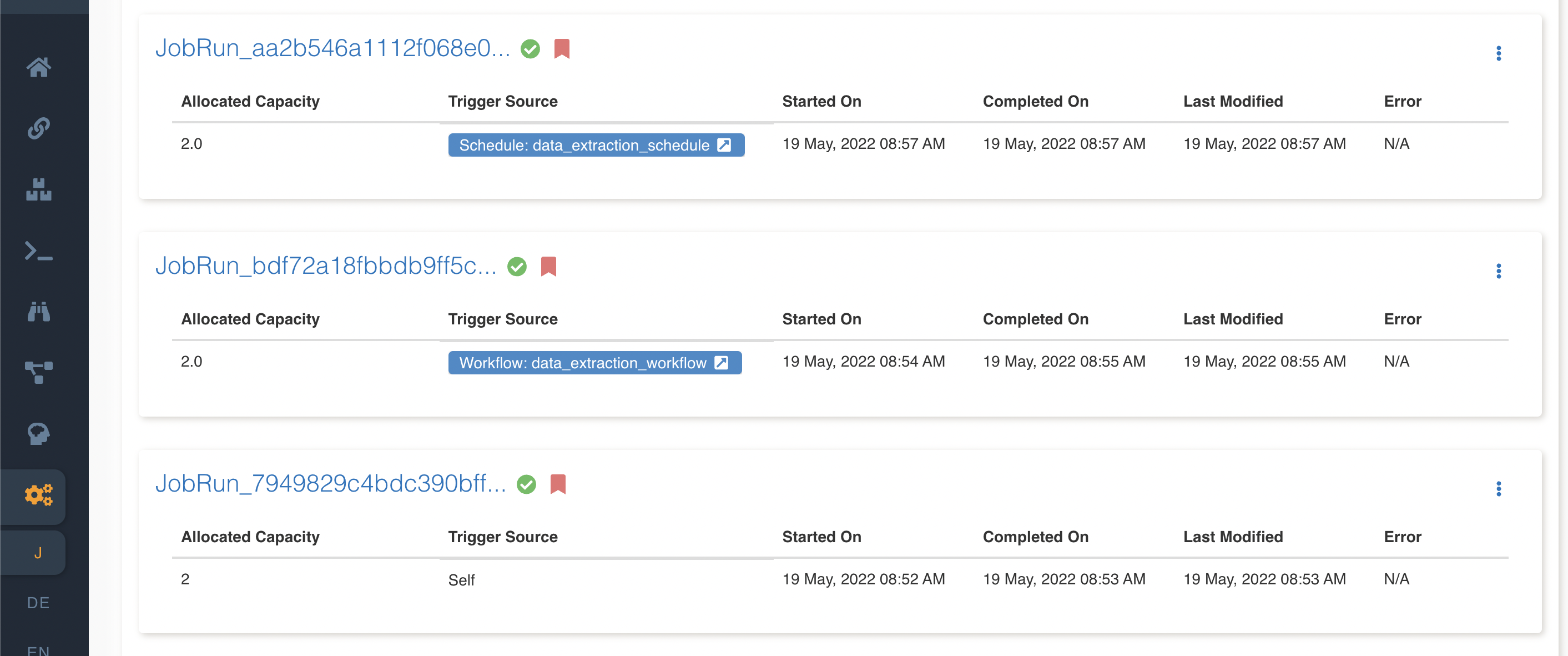
Download logs
Once a job status is updated, user can download the output (if any) and error logs (if any) through more (3 dots) option. The logs option is of 3 types:
- Output Logs (latest 1 MB): The latest 1 MB of the output logs for the job execution. This option will download the latest 1 MB of output logs immediately. If logs are not available, It'll display that 'No output logs available for the execution' message.
- Output Logs (All): All of the output logs for the job execution. This option will initiate log file creation. User will be notified through email once the log file is created. If there are no output logs then the log file will be empty.
- Error Logs: Error logs for the job execution. If logs are not available, It'll display that 'No error logs available for the execution' message.

If the user opts to download the full logs then it initiates the log file creation and the status will be 'triggered'. Status will be changed to 'available' and user will receive the email once log file is created. User can download the full logs using the same 'Output Logs (All)' option.

ETL Job Bookmark Operations
Amorphic ETL jobs provides options to bookmark their ETL job. This mechanism is used to track data processed by a particular run of an ETL job and that state information is called job bookmark. Below are the few operations that can be perform on bookmarking feature.
- Bookmark options: Bookmark options supported in ETL jobs
- Bookmark details in Job Executions: Job bookmark details displayed in Executions
- Download Manifest Files: Download job bookmark manifest files
- Reset Bookmark: Reset a job bookmark
Bookmark options
Three types of bookmark options are available:
- enable - Causes the job to update the state after a job run to keep track of previously processed data. User should also set transformation_ctx parameter in glue dynamic frame methods in ETL script. ETL job uses transformation_ctx to index the key to a bookmark state.
- disable - Default value. Job bookmark state is not stored and the job always processes the entire source datasets.
- pause - Process incremental data since the last successful run without updating the state of job bookmark. Job bookmark state is not updated and the last enabled job run state will be used to process the incremental data.
User can select the bookmark option while creating an ETL job or can also change the bookmark option by editing the job details. For job bookmarks to work properly, enable the job bookmark option in Create/Edit ETL job and also set the transformation_ctx parameter within the ETL script.
For more info on job bookmarks please refer documentation. Refer this documentation to understand the core concepts of job bookmarks in AWS Glue and how to process incremental data.
Below is the sample ETL snippet to set the transformation_ctx parameter:
InputDir = "s3://<DLZ_BUCKET>/<DOMAIN>/<DATASET_NAME>/"
spark_df = glueContext.create_dynamic_frame_from_options(connection_type="s3",connection_options = {"paths": [InputDir],"recurse" : True},format="csv",format_options={"withHeader": True,"separator": ",","quoteChar": '"',"escaper": '"'}, transformation_ctx = "spark_df")
Bookmark details in Job Executions
Bookmark option icon will be visible for each job run in the Execution window.

Download Manifest Files
When bookmark option is enabled and transformation_ctx parameter is set in DynamicFrames to read data, ETL job outputs a manifest file containing a list of processed files per path. The manifest file is stored in the temp location defined with the job. User can download the files from the job execution window.

Reset Bookmark
If user intends to reprocess all the data within the job then user can use the Reset Bookmark button in the job actions.

Clone Job
User can clone a job in Amorphic by clicking on clone button on the top right corner of the Job details page.
Clone Job page auto-populates almost all the metadata of job from which it is being cloned, reducing the effort to fill every field required for creating the job.
Once all the fields are filled, user can create a job by clicking the "Submit" button at the bottom right corner of the form.
Delete Job
If the user has sufficient permissions to delete the job then the job can be deleted using the 'Delete' (trash) button on the right side.
Once the job is deleted successfully then the job will not be displayed in the jobs listing page.