Data Profiling
Data profiling is the process of examining the data available from an existing information source and collecting statistics or informative summaries about the data. Data profiling also helps to understand anomalies and assess data quality.
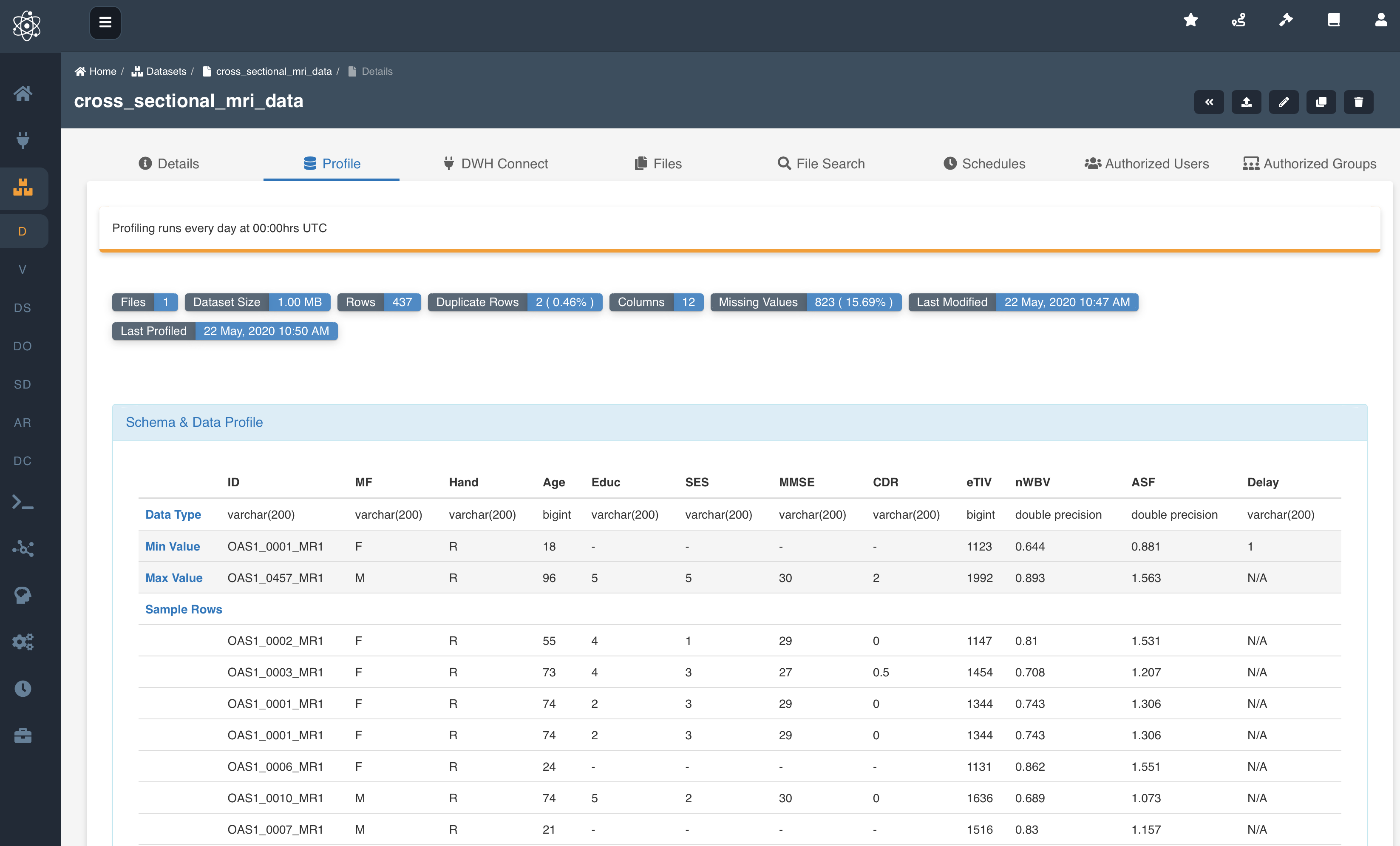
The above image shows data profile for data consisting of cross sectional MRI data from a sample of subjects diagnosed with Alzheimer's disease.
Enable Data profiling
The user can choose to enable data profiling by clicking edit dataset on datasets of his interest. It can be enabled/disabled at any point of time. Data profiling can only be enabled on structured datasets (eg: datasets of target location: s3-athena or auroramysql or redshift)

Following are the fields derived in a data profile:
- Files: Number of files in the dataset
- Dataset Size: Size of the dataset on s3 for datasets of target location 's3-athena' and size on datawarehouse for datasets of target location 'auroramysql or redshift'
- Rows: Number of rows present in the dataset
- Duplicate Rows: Number of non-unique rows present in the dataset
- Columns: Number of columns present in the dataset
- Missing Values: Number of empty cells in the dataset
- Last Modified: Time when the dataset was last edited by a user
- Last Profiled: Time when the data profile was extracted
- Data Type: Data types inferred when a dataset os registered.
- Min Value: Minimum value of each column
- Max Value: Maximum value of each column
- Sample Rows: A random sample of 10 rows from the dataset
Data profiling details will not be displayed for users with read-only access.
Update frequency of Data Profiling
Data profiling jobs run at 12 AM UTC everyday.
When do you update data profile for a dataset?
Data profile is updated only if data profiling is enabled by the user and there is an addition of files to the dataset in the last 24 hrs. This process is setup to avoid wastage of resources since data profile remains the same if no additional files are added.
Concurrency of data profiling jobs
Currently all data profiling jobs run with a concurrency factor of 5.
How long does it take for all data profiles to get updated?
Lets say there are 100 datasets to be profiled, each dataset takes 3 min (depends on the dataset size) for the data profile to be updated. With a concurrency factor of 5, total time taken will be 20*3min = 60min.
All the data profiles in this case should be updated by 1AM UTC.
What happens in case of failures?
In cases where a data profile fails to be extracted the error is displayed on the profile tab and an email alert is sent to the subscribed user.