
External Datasets
External datasets on amorphic let users consume their existing data present in S3 buckets directly without having to ingest them into a new amorphic dataset.
How to Create External Datasets?
Users can create external datasets by setting the Dataset Type attribute to 'external' and providing the source s3 location as the Dataset S3 Path. External datasets can be targeted to S3 and Lakeformation target locations.
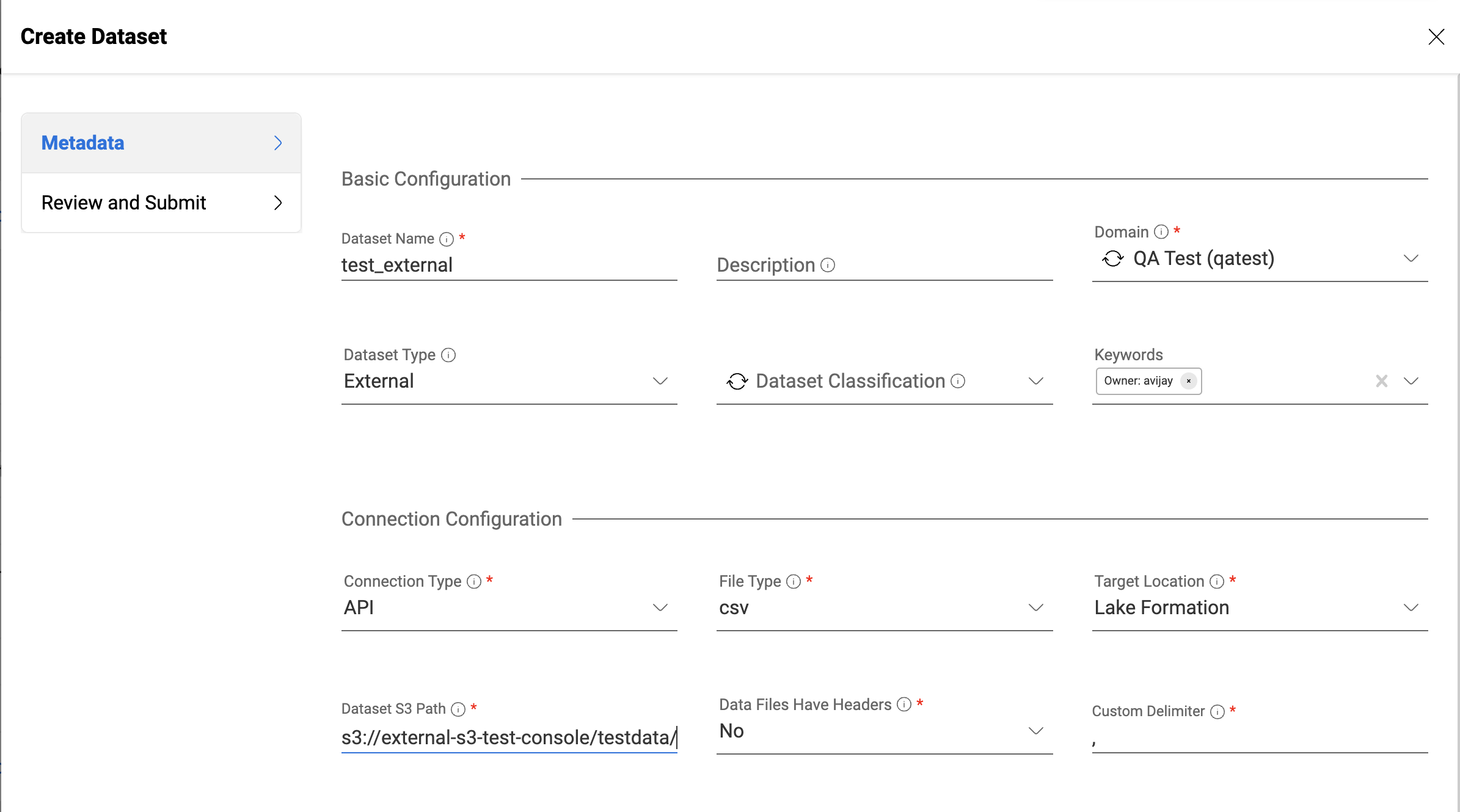
On creation of the dataset, users will be provided with a Dataset Role Arn and a bucket policy. They need to attach the bucket policy to the source bucket as part of Dataset S3 path for amorphic to access the data in it.
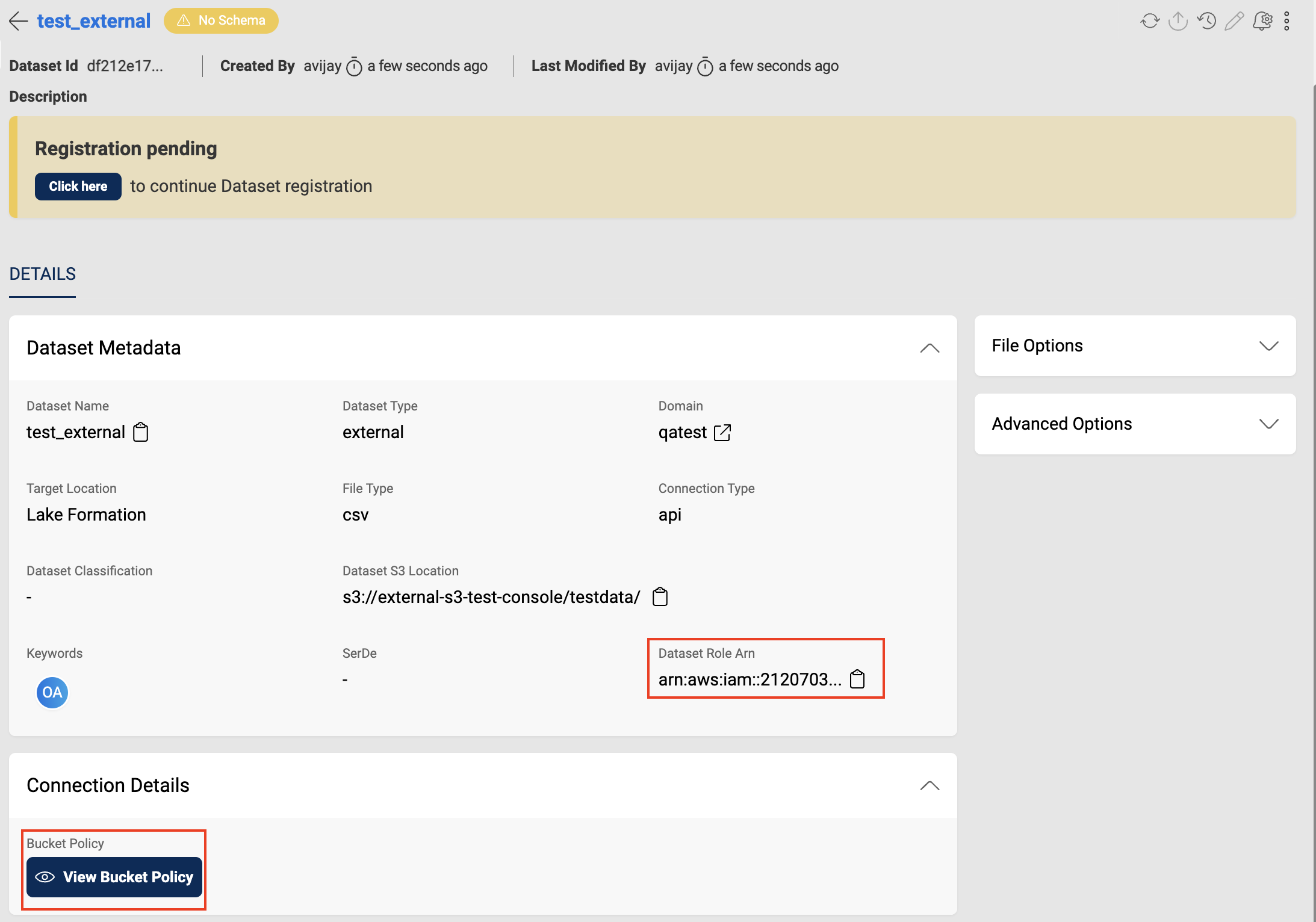
Partitioned Datasets
If the data in the source S3 location is partitioned, users need to specify this while completing the dataset registration. On completing the dataset registration, users need to run the MSCK REPAIR TABLE query through the query engine to load the partitions into glue.
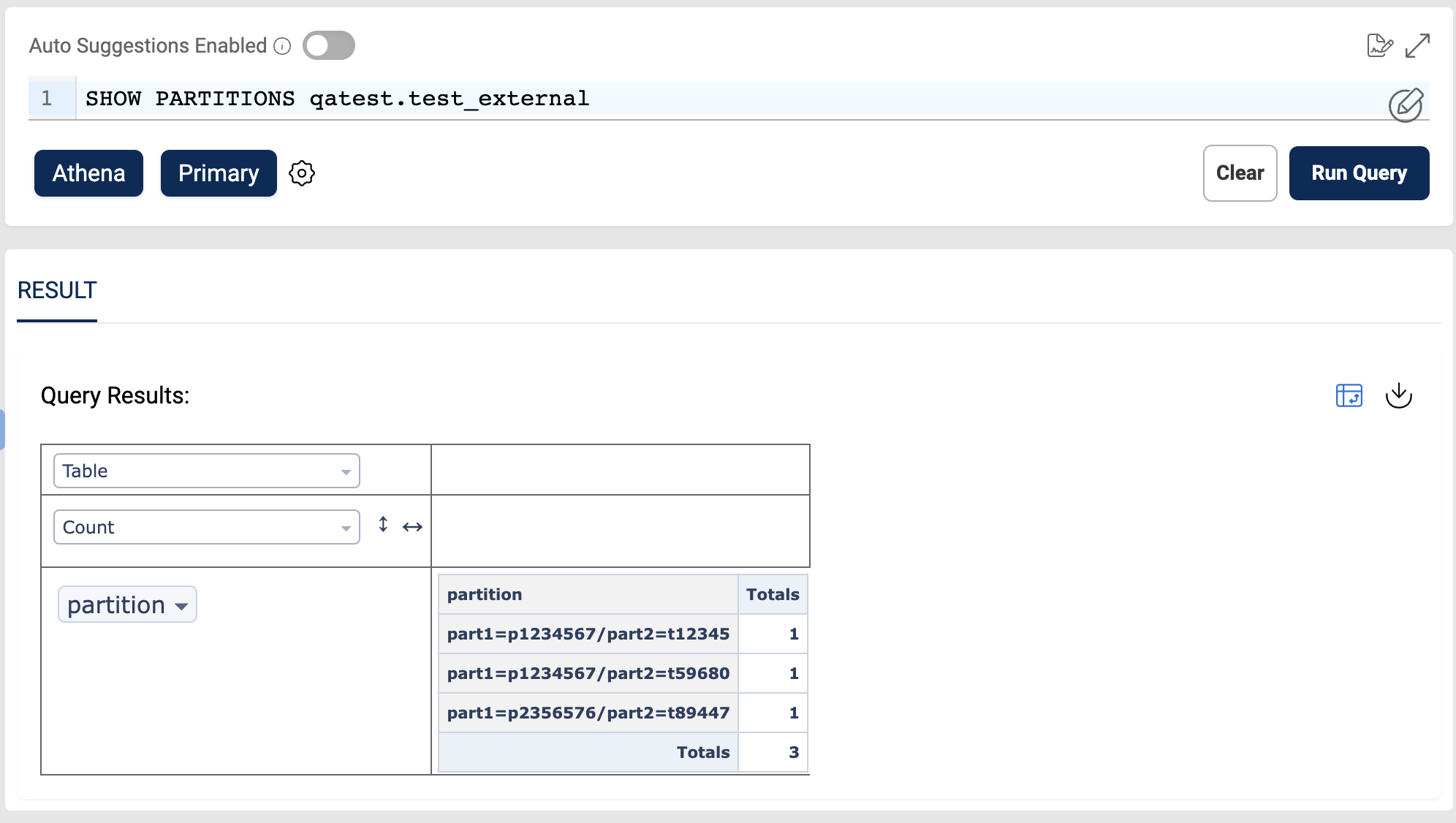
To view the partitions in glue, Users can run SHOW PARTITIONS query in 'Query Engine' against the specific external dataset.
Querying Datasets
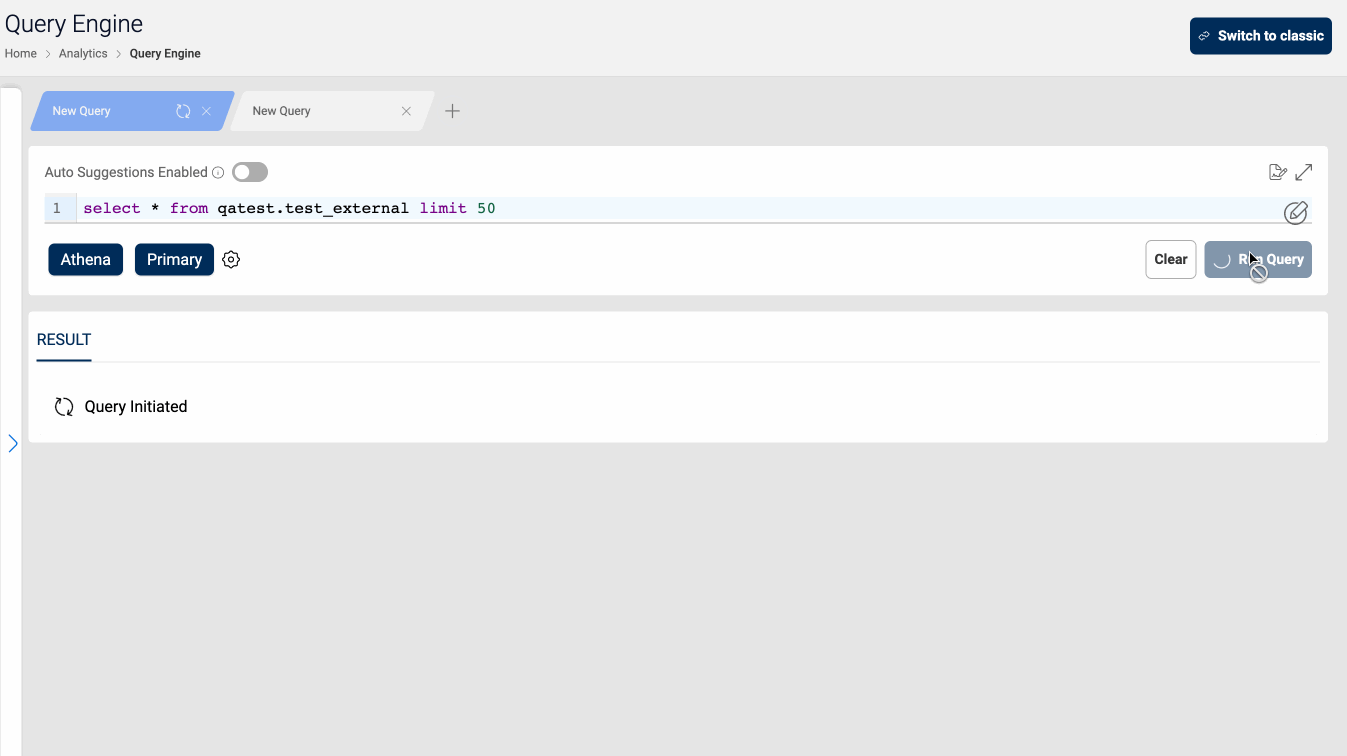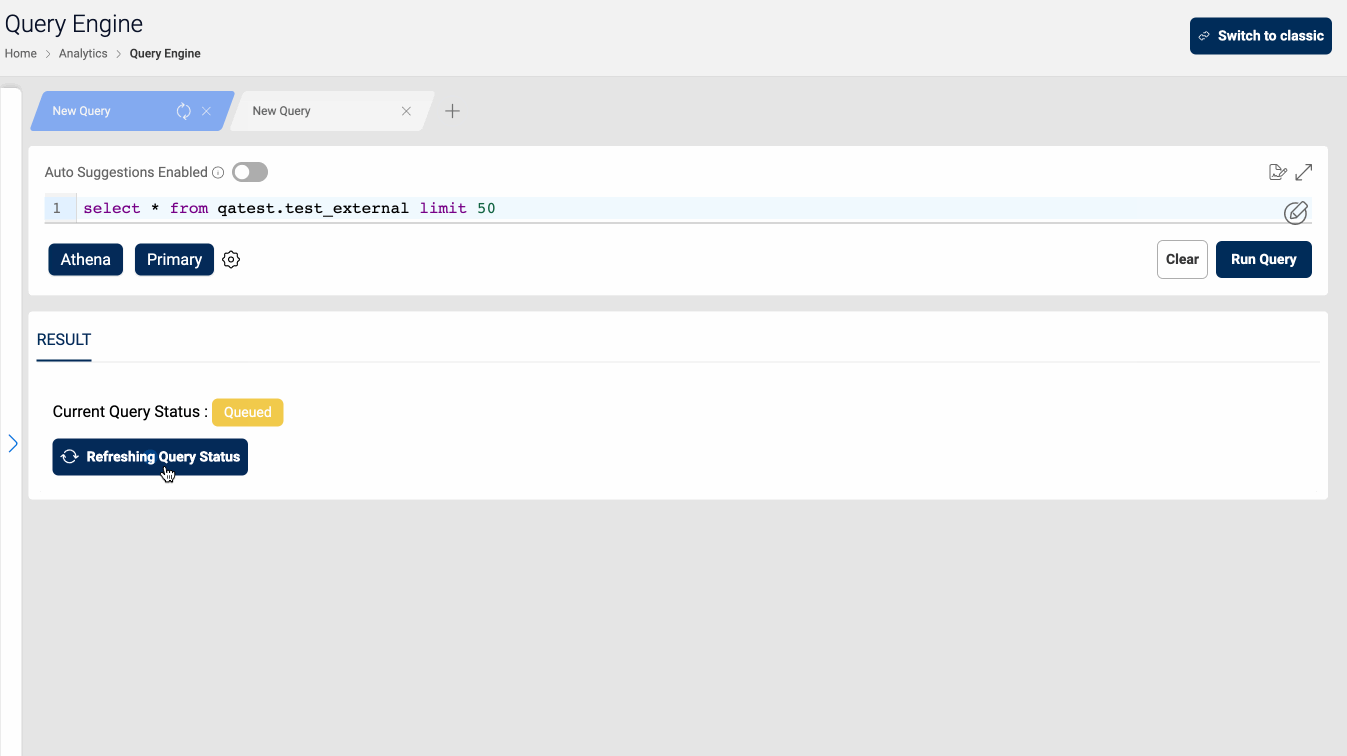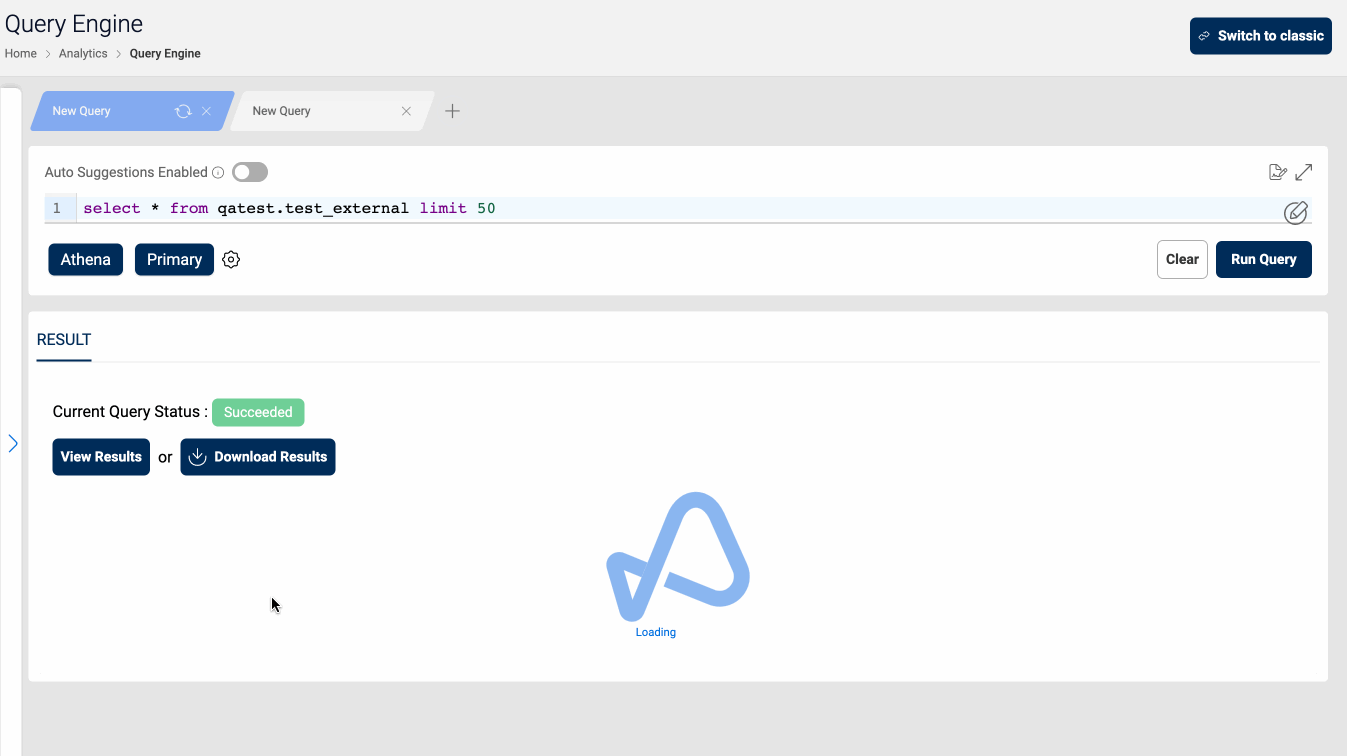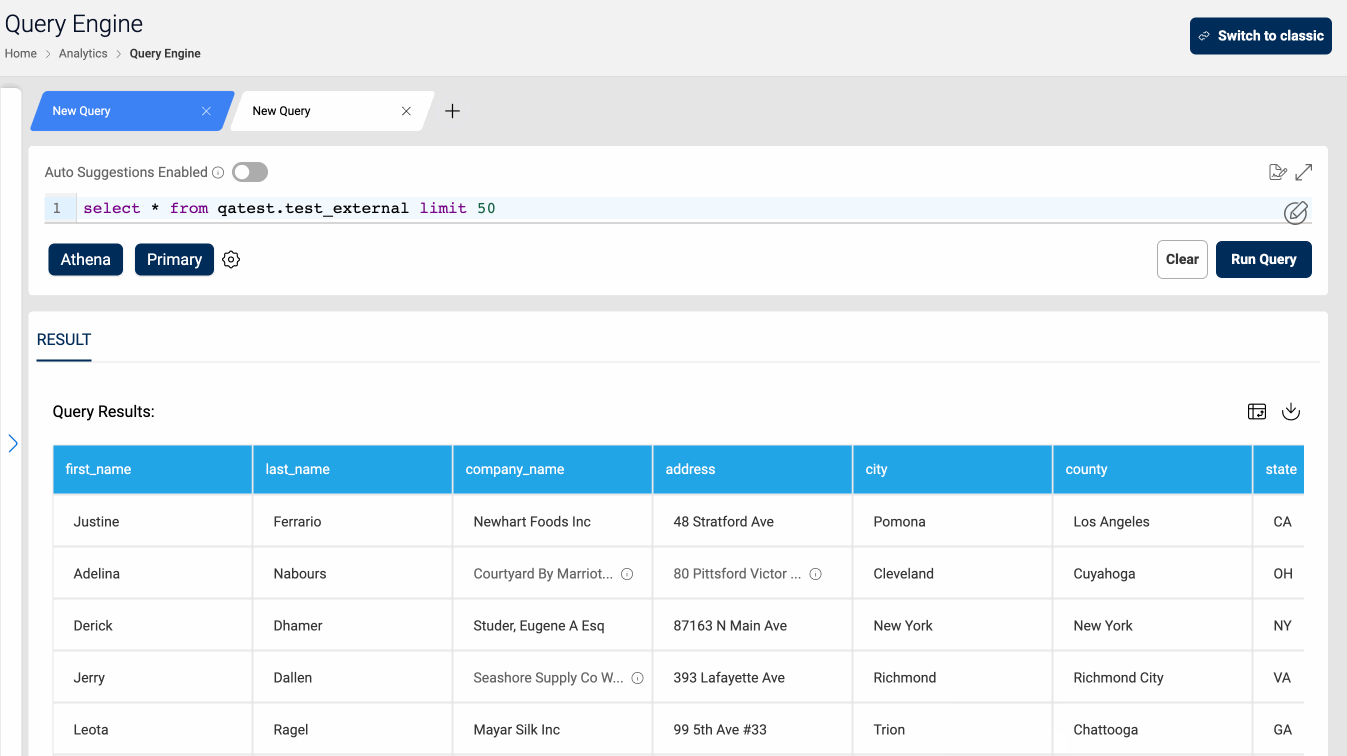
Querying the datasets through query engine is the same as for internal datasets. The queries supported on top of external datasets are:
- SELECT
- SHOW PARTITIONS
- ALTER TABLE ADD PARTITION
- ALTER TABLE DROP PARTITION
- ALTER TABLE RENAME PARTITION
Dataset Access From ETL Jobs and Notebooks
In order to consume the data from ETL jobs or notebooks, users should create STS credentials with the dataset role, create boto3 session and use them to retrieve the S3 data. The code snippet below shows an example of listing objects in the source S3 path from an ETL job:
import boto3
DATASET_ROLE_ARN = 'arn:aws:iam::XXXXXXXXXXXX:role/<your-external-dataset-role-name>' ### The External Dataset Role Arn
S3_BUCKET_NAME = '<your-s3-bucket-name>'
AWS_REGION = '<region-where-amorphic-is-deployed>'
# Getting the dataset role credentials
sts_client = boto3.client('sts', AWS_REGION)
sts_credentials = sts_client.assume_role(
RoleArn=DATASET_ROLE_ARN,
RoleSessionName='job-role',
DurationSeconds=900
)['Credentials']
session = boto3.Session(
aws_access_key_id=sts_credentials['AccessKeyId'],
aws_secret_access_key=sts_credentials['SecretAccessKey'],
aws_session_token=sts_credentials['SessionToken']
)
s3_client = session.client('s3')
resp = s3_client.list_objects(Bucket=S3_BUCKET_NAME)
Views
Views can be created on top of external datasets with target location Lakeformation.
Restrictions
Each dataset can be attached to a maximum of 18 resources(ETL jobs/notebooks)
If an external dataset is created with a S3 path then that specific S3 path cannot be re-used to create another external dataset
File upload and other file operations are restricted on external datasets
Ingestion is restricted on external datasets
Dataset repair cannot be performed for external datasets
Data validation, malware detection, data profiling, data metrics collection, data cleanup and lifecycle policies are disabled for external datasets