
DynamoDB Datasets
Amorphic DynamoDB Datasets enable structured datasets, serving as a single source of truth across organizational departments. These datasets only support DynamoDB as a target location via API.
You can only create, update, and delete DynamoDB datasets through the API. Once you create a dataset, you can view its details, upload files, and perform other operations on it from the Amorphic portal.
How to Create DynamoDB Dataset?
You can create a new DynamoDB dataset in Amorphic by using the below API.
POST https://{{gateway_id}}.execute-api.{{region}}.amazonaws.com/{{environment}}/datasets
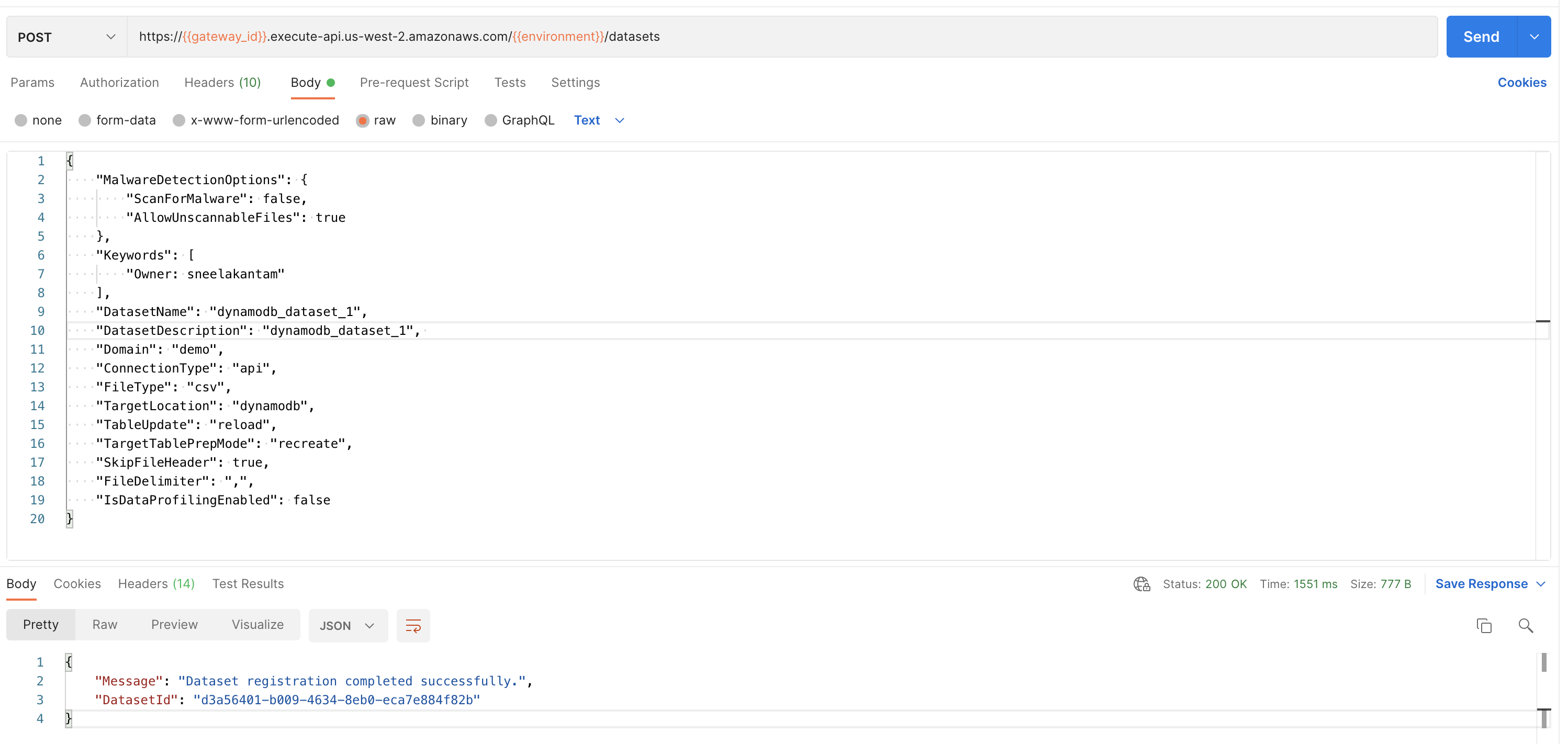
To create a new dataset, you need information like Domain, Connection type, and File Type. Here are the main details:
Amorphic datasets have a hierarchy. That means Files are connected with Datasets, and Datasets are connected to Domains. So, first create a Domain using Amorphic Administration. Then create a Dataset, and upload structured, semi-structured, or unstructured files to it.
For more info and required fields for dataset creation, read Create New Dataset.
Dataset Name: Name of the dataset. Dataset name must be 3-70 alphanumeric characters, with underscores (_) only. Your dataset name must be unique across the application.
Dataset Description: Description of the dataset. Please provide as much detail as possible. The full text of this field is searchable within the application.
Domain: Domain groups related datasets to keep them organized. This will be used when creating the DynamoDB table.
Data Classification: To classify the dataset with different categories to protect the data more efficiently. For example: PCI, PII, etc.
Keywords: Keywords for the dataset. Keywords are indexed and searchable within the application. Please choose meaningful keywords that will help you and others to easily find related datasets.
- Connection Type: Amorphic currently supports the following connection types:
- API: The default connection type, which can be used to manually upload files to the dataset. Refer to the Dataset Files documentation for more information on manual file uploads.
- JDBC: For ingesting data from a JDBC connection (as source) to the Amorphic dataset. Requires a schedule for data ingestion.
- S3: For ingesting data from an S3 connection (as source) to the Amorphic dataset. Requires a schedule for data ingestion.
- Ext-API: For ingesting data from an external API (as source) to the Amorphic dataset. Requires a schedule for data ingestion.
- File Type: The supported file types for DynamoDB datasets are CSV, TSV, XLSX, and Parquet.
- TargetTablePrepMode
- recreate
- truncate
- SkipFileHeader (Optional) : When Skip Trash is True old data is not moved to Trash bucket during the data reload process, default is true when not provided.
Based on the above reload settings, data reload process times can vary.
Target Location:
- DynamoDB: Files uploaded to the dataset (either manually or through ingestion) will be stored in the DynamoDB table.
Table Update: Currently, DynamoDB datasets support two update methods:
- Append: With this update method, data will be appended to the existing data.
- Reload: With this update method, data will be reloaded to the dataset. The following two options are exclusive for the Reload type of dataset.
Schema Publish
When you add a dataset to DynamoDB, you can use the API to set the dataset's schema and the keys for the DynamoDB table.
PUT https://{{gateway_id}}.execute-api.{{region}}.amazonaws.com/{{environment}}/datasets/{{dataset_id}}
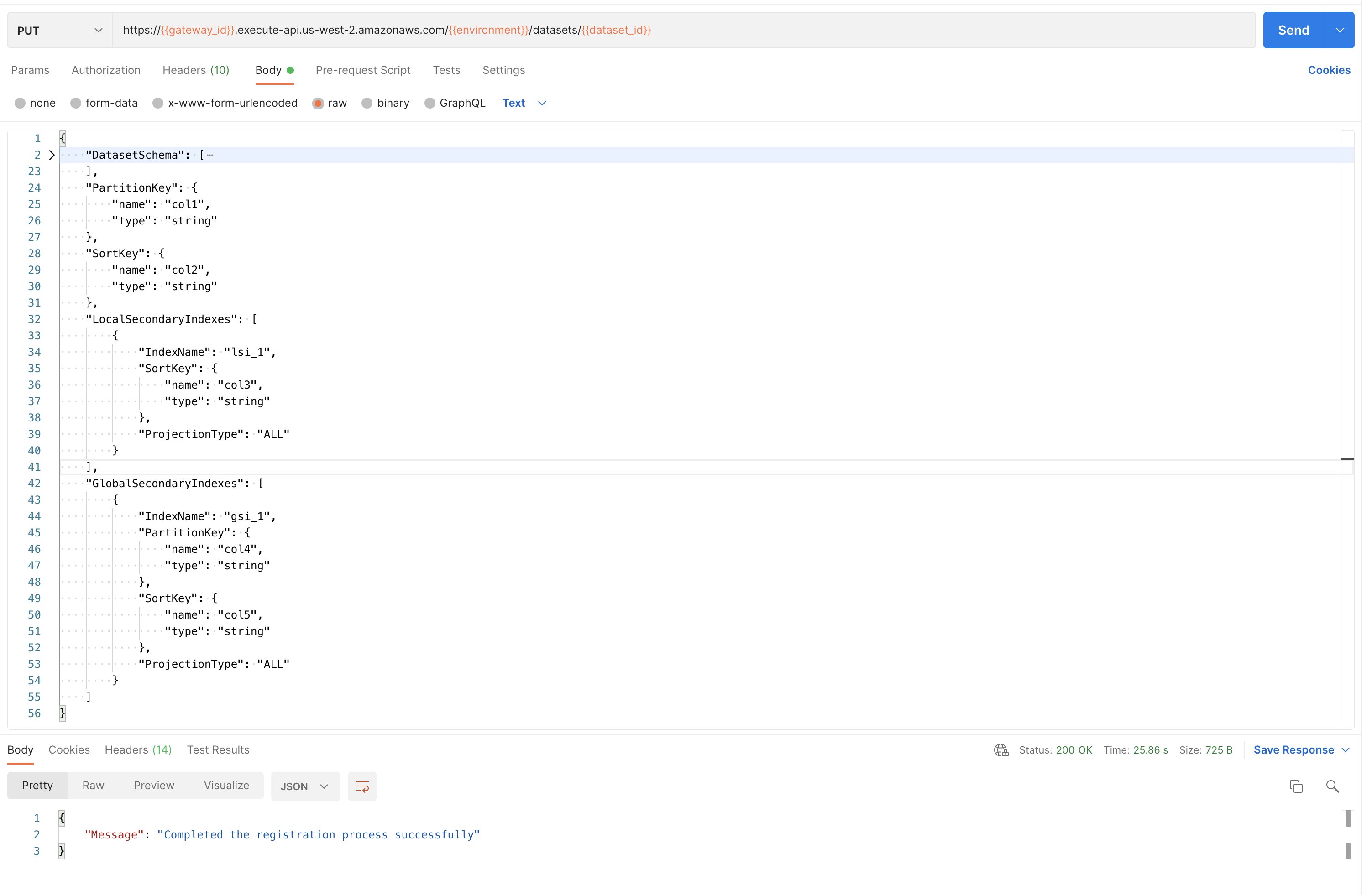
Details needed to publish schema & register dataset:
{
"DatasetSchema": [
{
"name": "string",
"type": "string"
}
],
"PartitionKey": {
"name": "string",
"type": "string"
},
"SortKey": {
"name": "string",
"type": "string"
},
"LocalSecondaryIndexes": [
{
"IndexName": "string",
"SortKey": {
"name": "string",
"type": "string"
},
"ProjectionType": "string"
}
],
"GlobalSecondaryIndexes": [
{
"IndexName": "string",
"PartitionKey": {
"name": "string",
"type": "string"
},
"SortKey": {
"name": "string",
"type": "string"
},
"ProjectionType": "string"
}
]
}
- DynamoDB datasets support STRING, NUMBER, and BINARY data types.
- If the Dataset publish schema (PUT) call times out after 30 secs, delete the dataset from the Amorphic portal and try creating/publishing schema again via API.
- DatasetSchema: Schema of dataset w/ columns (name & type). Must contain all expected columns from input.
- PartitionKey: Attribute of primary key. No two items can have same value if only PartitionKey. Composite of PartitionKey & SortKey must uniquely identify item. For more info see AWS Documentation.
- SortKey: SortKey is an optional attribute of a primary key. It and the PartitionKey must uniquely identify a composite. For more info, see the AWS Documentation.
- LocalSecondaryIndexes: Create an index w/ same partition key as dataset, but different sort key. LSI is optional & user must provide SortKey following primary key rules. Can create only 5 Local Secondary Indexes in dataset; for more info refer AWS Documentation.
- IndexName: A unique name for the local secondary index.
- SortKey: SortKey is similar to the table SortKey the composite of PartitionKey and SortKey must be uniquely identify an item in the dataset and follows the same rules within local secondary indexes as well.
- ProjectionType: Represents attributes that are copied (projected) from the table into the local secondary index. User can provide one of below options:
- ALL: All of the table attributes are projected into the index.
- KEYS_ONLY: Only the index and primary keys are projected into the index.
- GlobalSecondaryIndexes: A GSI can be created during dataset creation or by updating the dataset, with a max of 20 per dataset. PartitionKey and SortKey must follow primary key rules. For more info, refer to AWS Documentation.
- IndexName: A unique name for the global secondary index.
- PartitionKey: PartitionKey is similar to the table PartitionKey follows the same rules within global secondary indexes as well.
- SortKey: SortKey is similar to the table SortKey the composite of PartitionKey and SortKey must be uniquely identify an item in the dataset and follows the same rules within global secondary indexes as well.
- ProjectionType: Represents attributes that are copied (projected) from the table into the global secondary index. User can provide one of below options:
- ALL: All of the table attributes are projected into the index.
- KEYS_ONLY: Only the index and primary keys are projected into the index.
Update metadata
You can add/delete Global Secondary Indexes to/from DynamoDB datasets.
PUT https://{{gateway_id}}.execute-api.us-west-2.amazonaws.com/{{environment}}/datasets/{{dataset_id}}/updatemetadata
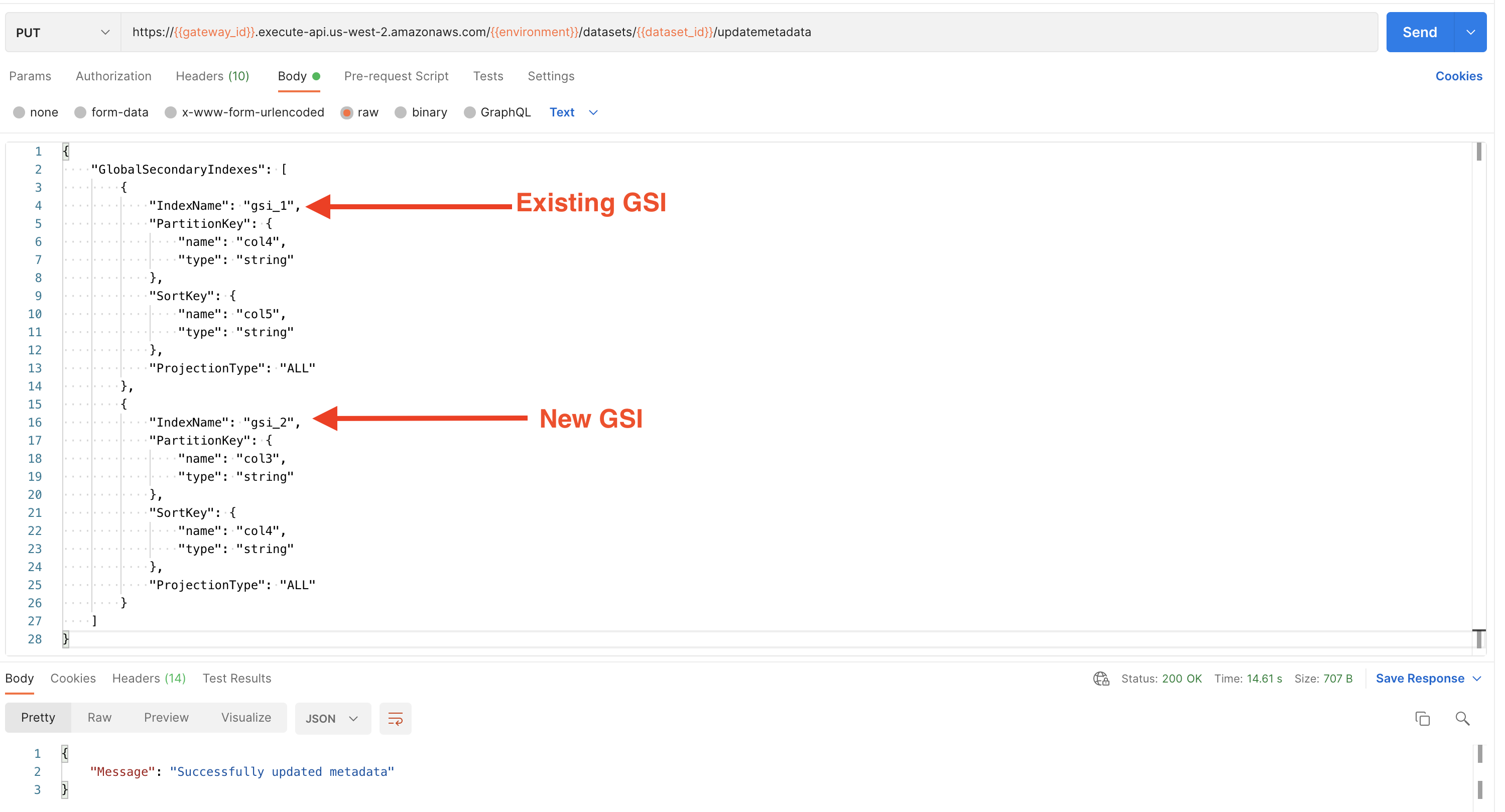
Following are the details are required to update global secondary index.
{
"GlobalSecondaryIndexes": [
{
"IndexName": "string",
"PartitionKey": {
"name": "string",
"type": "string"
},
"SortKey": {
"name": "string",
"type": "string"
},
"ProjectionType": "string"
}
]
}
With a single API call, users can only add or delete one global secondary index. If multiple operations are needed, users must make consecutive calls and perform them.
The PUT API call body must include the list of GSI's that the user wants in the dataset. To delete an existing GSI and add a new one, two separate API calls must be made: one to remove the GSI from the list, and another to add the new GSI.
View Dataset
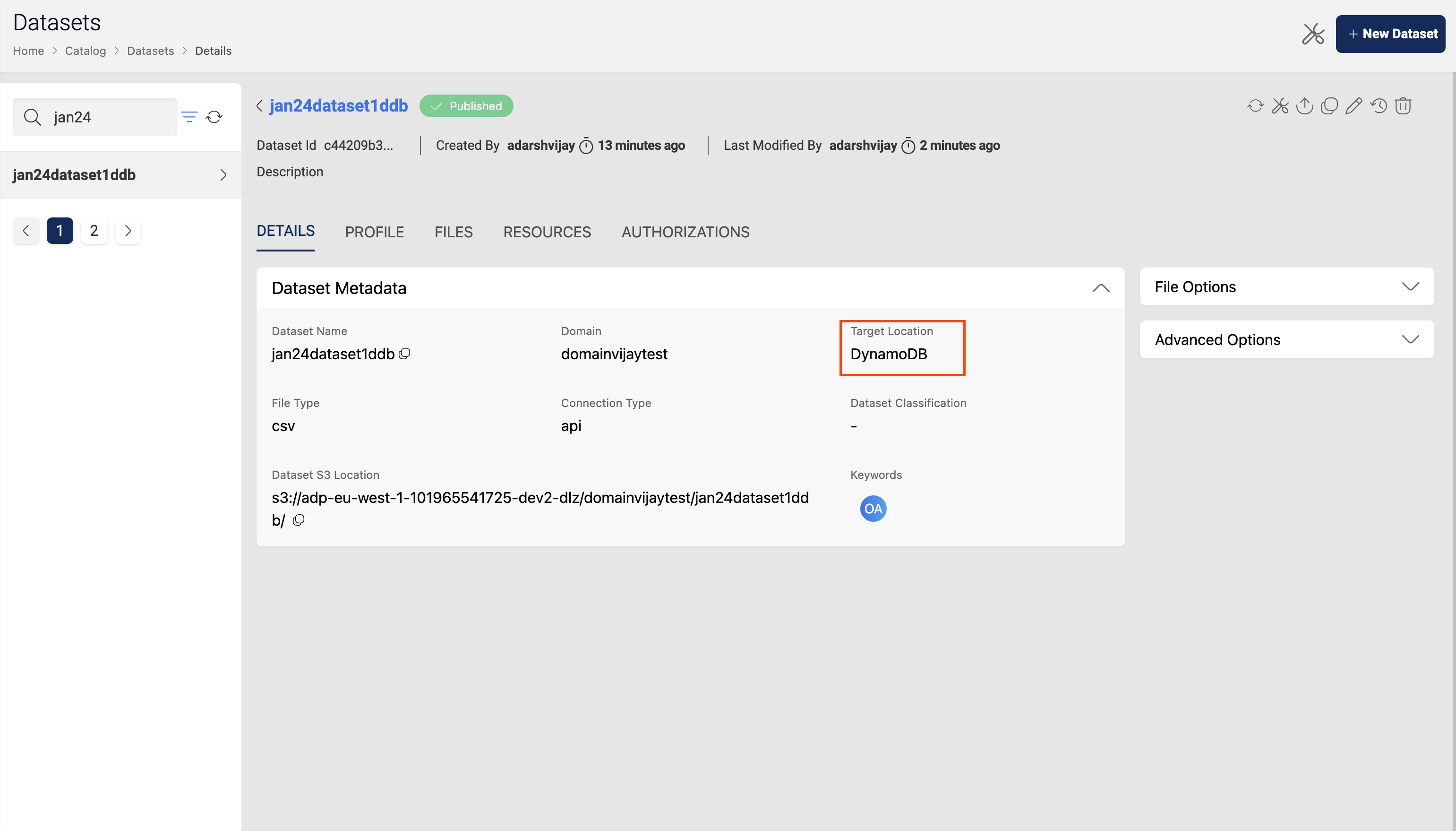
You can view DynamoDB dataset details in view details. Please check the documentation on View Dataset for more details on viewing a dataset.
DynamoDB Table Name and SSM Parameter Details
After schema registration step, dynamodb table creation process is triggered and a table name with below naming convention is created. Also a SSM parameter is created as part of the same process which contains dynamodb table name. This SSM parameter can be used in ETL jobs to get the latest dynamodb table name and perform ETL operations.
DynamoDB table naming convention: <PROJECTSHORTNAME>_<DOMAINNAME>_<DATASETNAME>_<RANDOM_5_CHAR_STRING>
SSM parameter naming convention: <PROJECTSHORTNAME>_<DOMAINNAME>_<DATASETNAME>
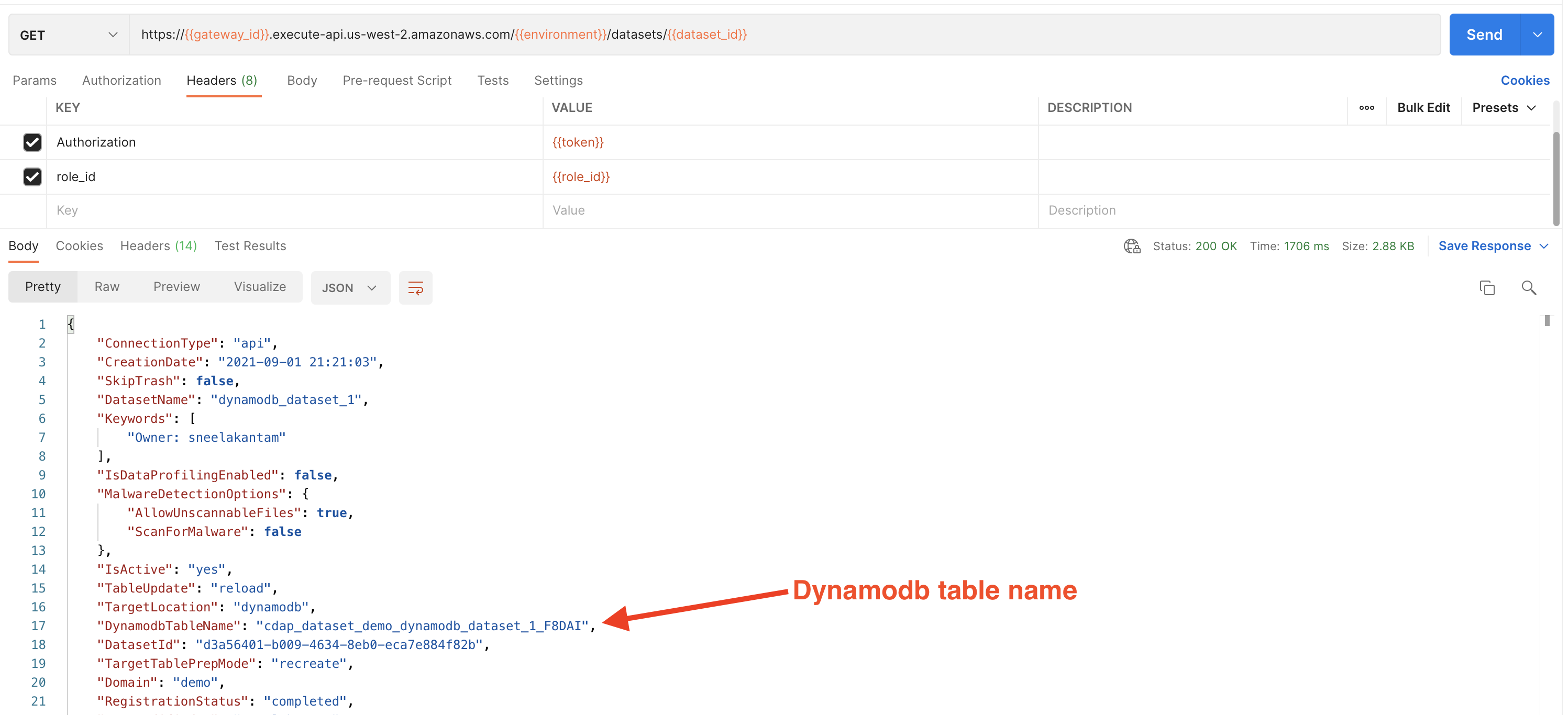
If UpdateType is reload, a new DynamoDB table will be created, old table deleted, and the latest table name can be acquired from the SSM parameter value.
Upload files
You can upload files manually to dataset if connection type is API (default). Check Dataset files for details. You can use the same approach for DynamoDB datasets.
Access DynamoDB Datasets from ETL Jobs
User can add DynamoDB datasets to their ETL jobs same as any other datasets by editing an existing ETL job or while creating a new ETL job in Amorphic UI. When user adds a DynamoDB dataset to read/write access in ETL job then the read/write access will be provided on DynamoDB table and the SSM parameter as well.
DynamoDB dataset with WRITE access: When WRITE access is given in ETL jobs, users can perform operations on a DynamoDB table, such as:
PutItem
UpdateItem
DeleteItem
BatchWriteItem
GetItem
BatchGetItem
Scan
Query
ConditionCheckItemDynamoDB dataset with READ access: User can perform READ ops on DynaDB table when given access in ETL jobs.
GetItem
BatchGetItem
Scan
Query
ConditionCheckItem
Sample ETL Job script
Below is a sample ETL script to access get dynamodb dataset SSM parameter value and query the DynamoDB table.
import os
import sys
import datetime
import json
import boto3
from boto3.dynamodb.conditions import Key
from awsglue.utils import getResolvedOptions
AWS_REGION = 'us-west-2'
DYNAMODB_RES = boto3.resource('dynamodb', AWS_REGION)
ssm_client = boto3.client('ssm', AWS_REGION)
parameter_key = "cdap_dataset_demo_dynamodb_dataset_1"
response = ssm_client.get_parameter(Name=parameter_key)
dynamodb_table_name = response['Parameter']['Value']
print("DynamoDB table name - {}".format(dynamodb_table_name))
dynamodb_table = DYNAMODB_RES.Table(dynamodb_table_name)
ddb_item = dynamodb_table.query(
KeyConditionExpression=Key('imdb_id').eq('tt0047966')
)
print("Get item from DynamoDB: {}".format(json.dumps(ddb_item, indent=4, default=str)))
full_table_scan = dynamodb_table.scan()
data = full_table_scan['Items']