
Redshift Datasets
Amorphic provides users with the ability to store csv/tsv/xslx files in s3 with Redshift datasets as the target location, with an optional partial data validation enabled by default. This validation helps detect and correct corrupt or invalid data files, and supports data types such as strings/varchar, integers, double, boolean, date, timestamp, and complex data structures. However, there are limitations to the CSV parser recommended by AWS Athena, such as not supporting embedded line breaks or empty fields in columns defined as a numeric data type. In this case, it is suggested to import the data as string columns and then cast it to the required data type through views.
The AWS Athena CSV Parser/SerDe has the following limitations:
- Embedded line breaks in CSV files are not supported.
- Empty fields in columns defined as a numeric data type are not supported.
As a workaround, you can import them as string columns and create views on top of it by casting them to the required data types.
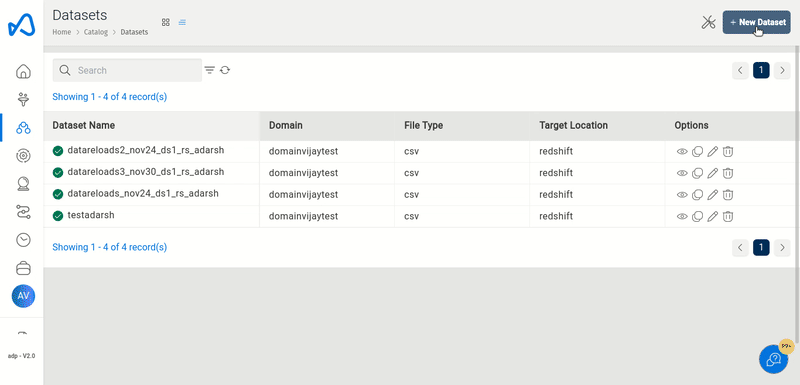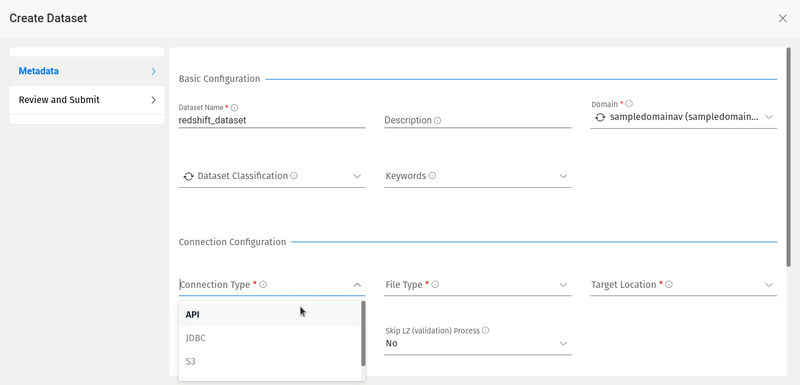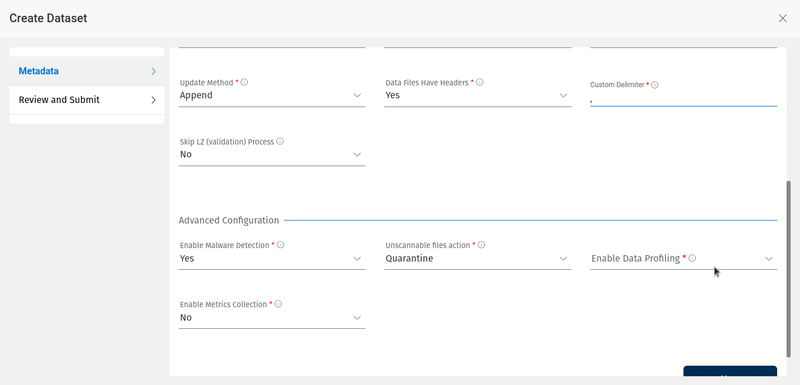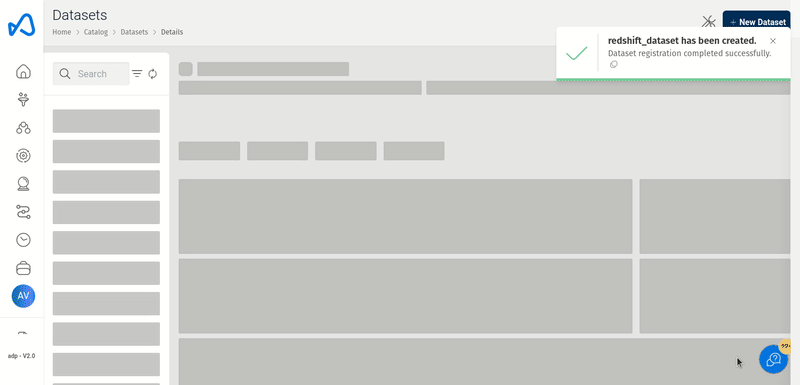
Create Redshift Datasets
You can create new datasets with Redshift as target locations. Currently, only structured data with CSV, TSV, XLSX, AND PARQUET file formats are supported.
Redshift Datasets Permissions
- The owner of the Redshift dataset has
USAGEandCREATEpermissions on the Redshift cluster schema (Domain), as well as'SELECT', 'INSERT', 'DELETE', 'UPDATE'permissions on the Redshift cluster table (Dataset). - A read-only user has
USAGEpermission on the Redshift cluster schema (Domain), as well asSELECTpermission on the Redshift cluster table (Dataset).
Redshift DBT support
With 1.13 release users can create their own tables and views while working on dbt however sync back data from these new tables and views is not supported in this release.
Users need to provide existing domain (schema) name as dbt schema and they will be able to modify and create new tables/views under the schema.
Redshift Column/Table Constraints and Attributes Support
With 1.14 release users can create Redshift datasets with more table constraints and column constraints and attributes. To know more, refer AWS Redshift Create Table documentation.
Table Constraints:
- UNIQUE : Specifies that the column can contain only unique values.
- PRIMARY KEY : Specifies that the column is the primary key for the table.
infoNote Unique and Primary key constraints are informational only and they aren't enforced by the Redshift. Redshift automatically convert columns that defined as PrimaryKey to NOTNULL by default.
- Column Attributes:
- IDENTITY : Specifies that the column is an IDENTITY column. To add identity column, user need to provide values for Identity Column Name, Seed and Step Values.
- Column Constraints:
- NOT NULL : Specifies that the column isn't allowed to contain null values.
From Amorphic 2.3 onwards, Users can create Redshift datasets with additional datatypes such as super and varbyte.
- Super:
- It can store any semistructured data or values.
- The given values must be appropriately serilaized to Json inorder to be stored properly in the backend
- We cannot define Super columns as either a distribution or sort key. For more limitations, refer AWS Redshift Super datatype limitations
- Varbyte:
- It supports storing binary values
- CSV, TSV and XLSX treats the given column values in the file as hexadecimal and converts them to binary while storing it in the backend. However it will display the values only in hexadecimal format.
- For Parquet datatype, data needs to ingested properly for varbyte column by properly converting into hexadecimal. Incorrect format results in an error or value being converted to hexadecimal wrongly and captured in the backend.
- We cannot define Varbyte columns as sort key for interleaved sort type.
Redshift Data Conversion Parameters Support
With the release of version 1.14, users will be able to create Redshift datasets with Data Conversion Parameters. When data is loaded into Redshift, Amorphic will implicitly convert strings in the source data to the data type of the target column.
Data Conversion Parameters can be used to specify a conversion that is different from the default behavior, or if the default conversion results in errors when data is loaded into the Redshift database. For more information, please refer to the AWS Data Conversion Parameters documentation.
Below are different Data Conversion Parameters that are supported:
'ACCEPTANYDATE', 'ACCEPTINVCHARS', 'BLANKSASNULL', 'DATEFORMAT', 'EMPTYASNULL', 'ENCODING', 'ESCAPE', 'EXPLICIT_IDS', 'FILLRECORD', 'IGNOREBLANKLINES', 'NULL', 'REMOVEQUOTES', 'ROUNDEC', 'TIMEFORMAT', 'TRIMBLANKS', 'TRUNCATECOLUMNS'
For data conversion parameters DATEFORMAT, TIMEFORMAT and NULL, the user must provide a valid argument. Arguments for ENCODING and ACCEPTINVCHARS are optional. No arguments are required for all other data conversion parameters.
You can find data conversion parameters for Redshift datasets in the Profile section. The picture below shows how to add or edit the data conversion parameters for a Redshift dataset you have registered.
For Redshift use cases with a large number of incoming files, the user should turn ON dataload throttling and set a maximum limit of 90 for redshift.