
Run data reload
Create a dataset with Reload type in create dataset page. For information on how to create a dataset please visit Create new dataset
The following picture depicts the create dataset page in Amorphic
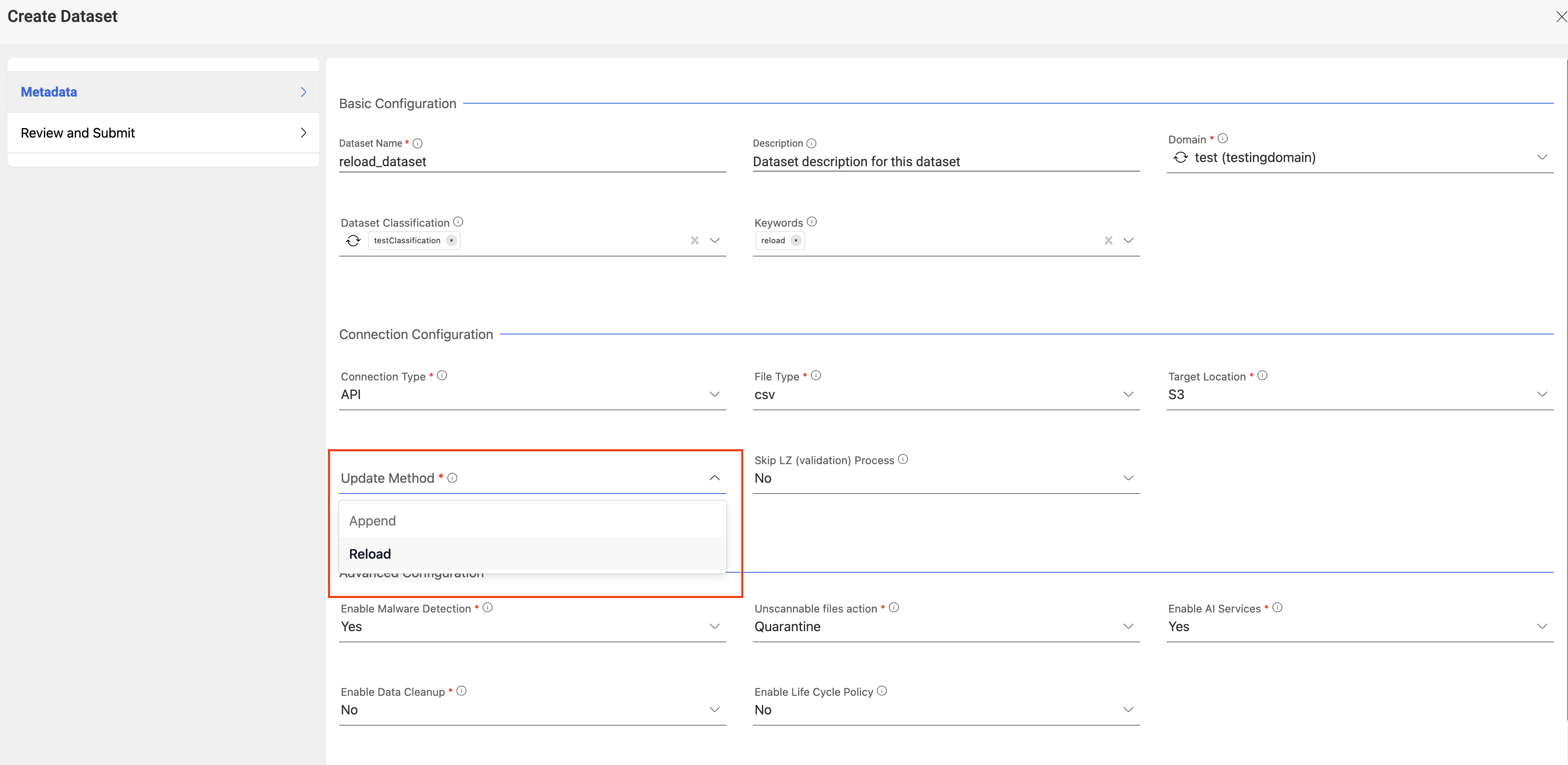
Data reload for a dataset can be done in two ways, either via API or via UI.
Reload through UI
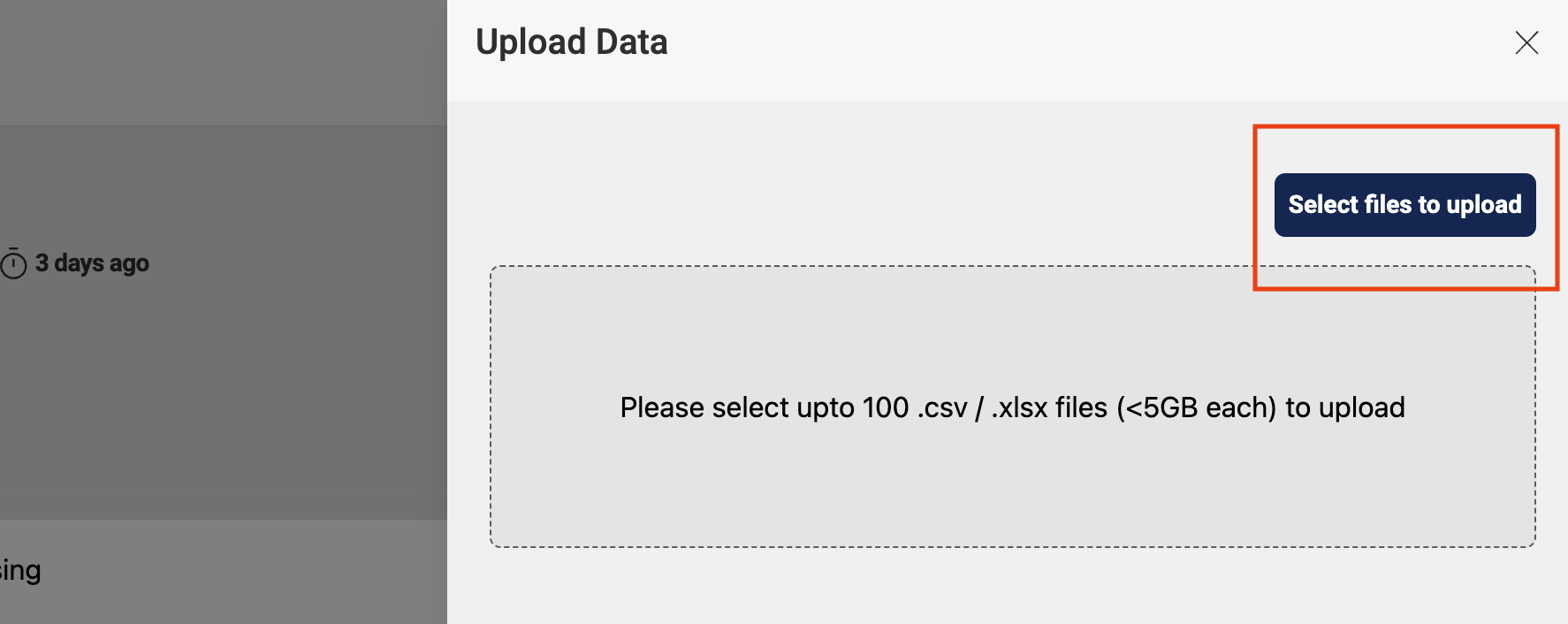
Upload the files from UI with the Upload Data option on the top and then proceed with file upload. A single or multiple files can be uploaded at the same time.
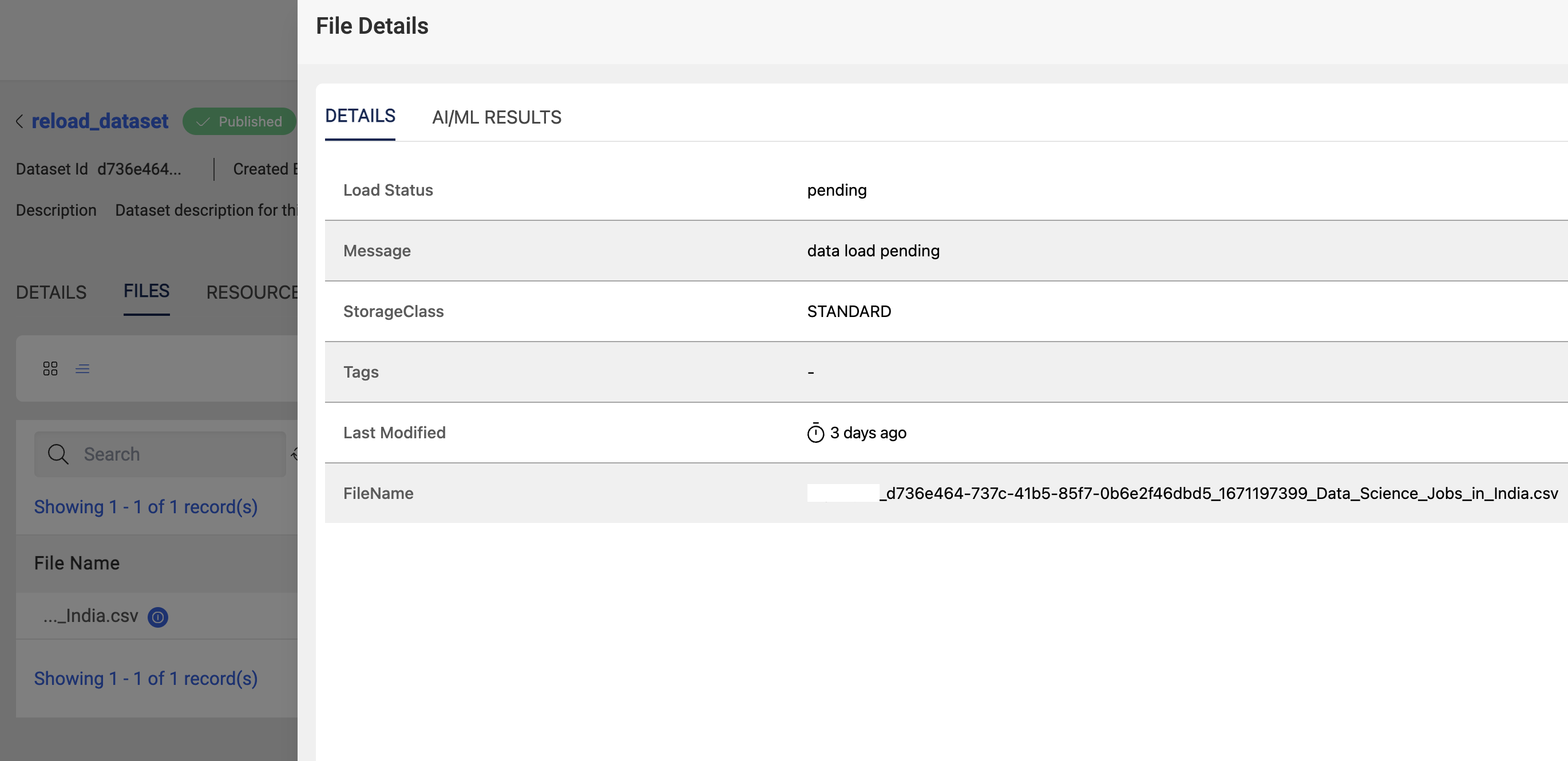
After successful files upload, files will be pending status which needs user action for further processing. Below is the example of file status after successful file upload.
From FileStatus tab select Pending files which redirects to a different page which shows all the files that are in pending status. A user can select/de-select the files to be processed from this page.
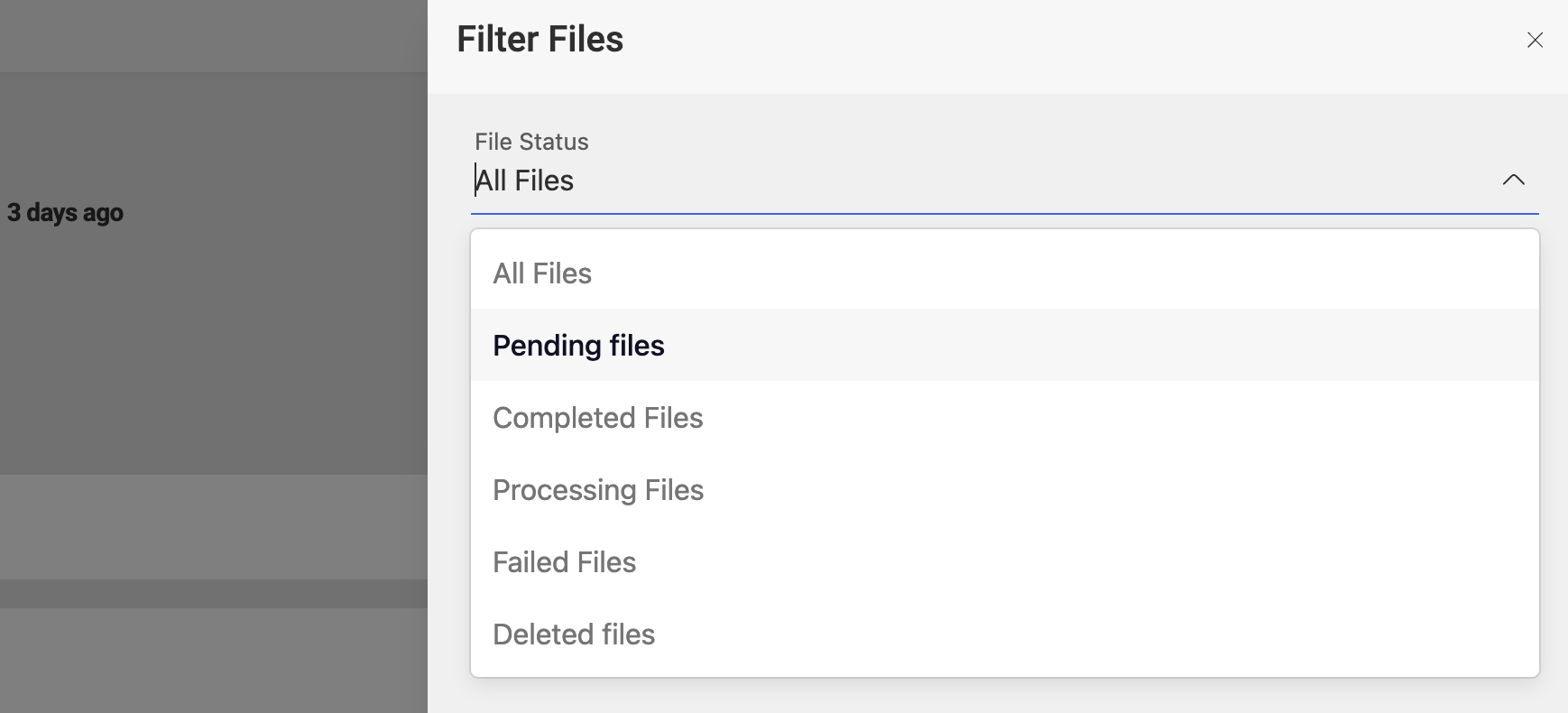
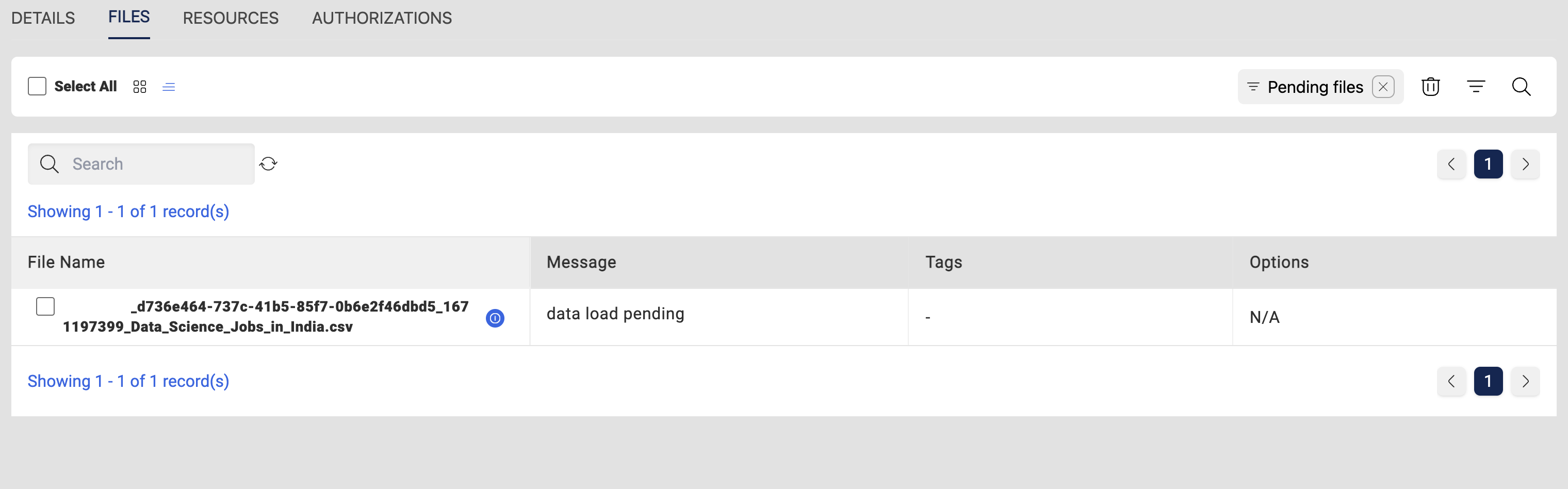
User have to select the files that are required for processing from this pending files page & then click on the Process Files option at the bottom of the page which starts the Data Reload process and will continue running in the background.
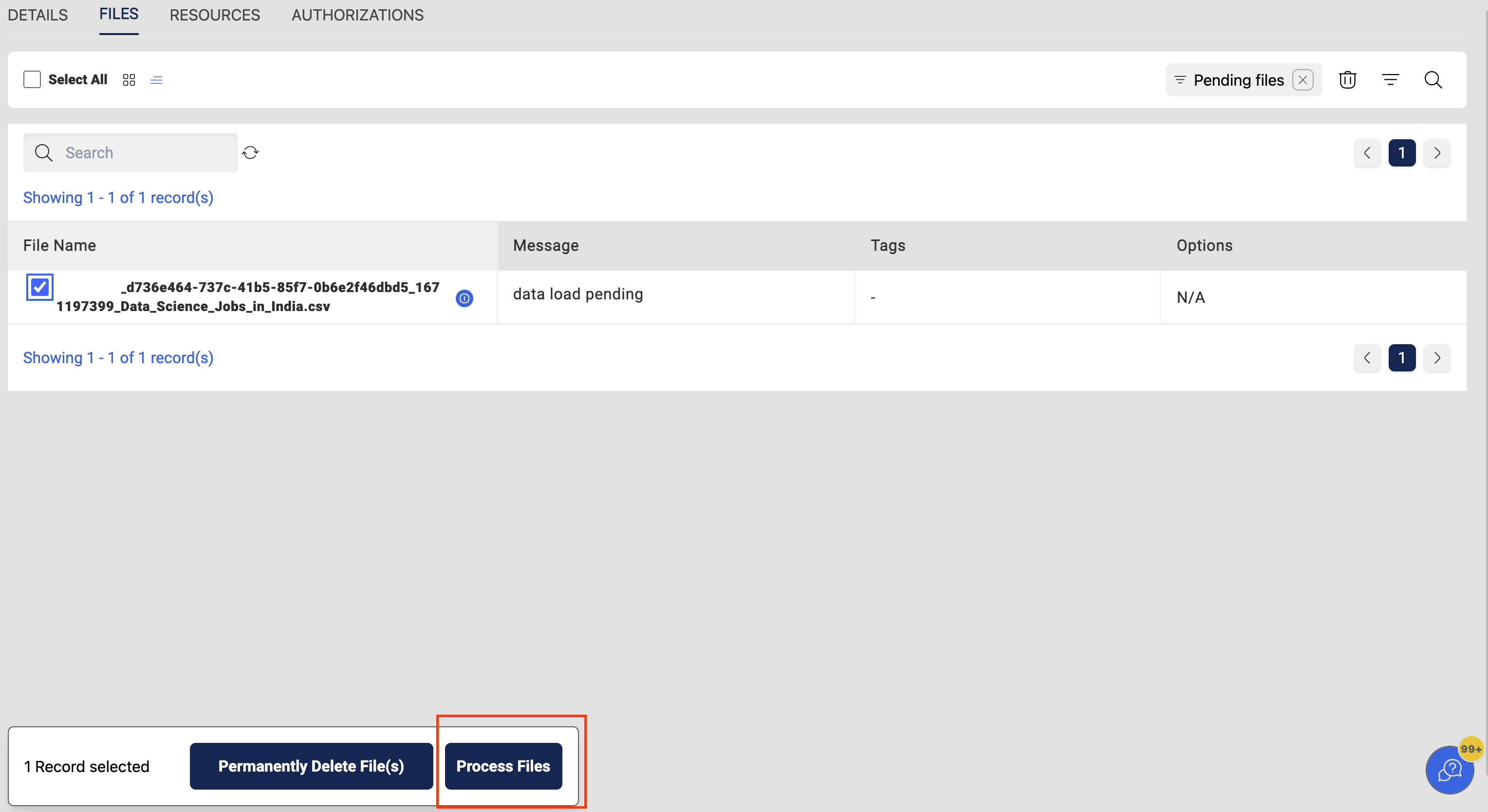
Overall status of the data reload can be seen from the executions page and the status of selected files will change to processing during the reload.
After the successful completion of data load, file statuses will be changed to completed and same with the Execution status.
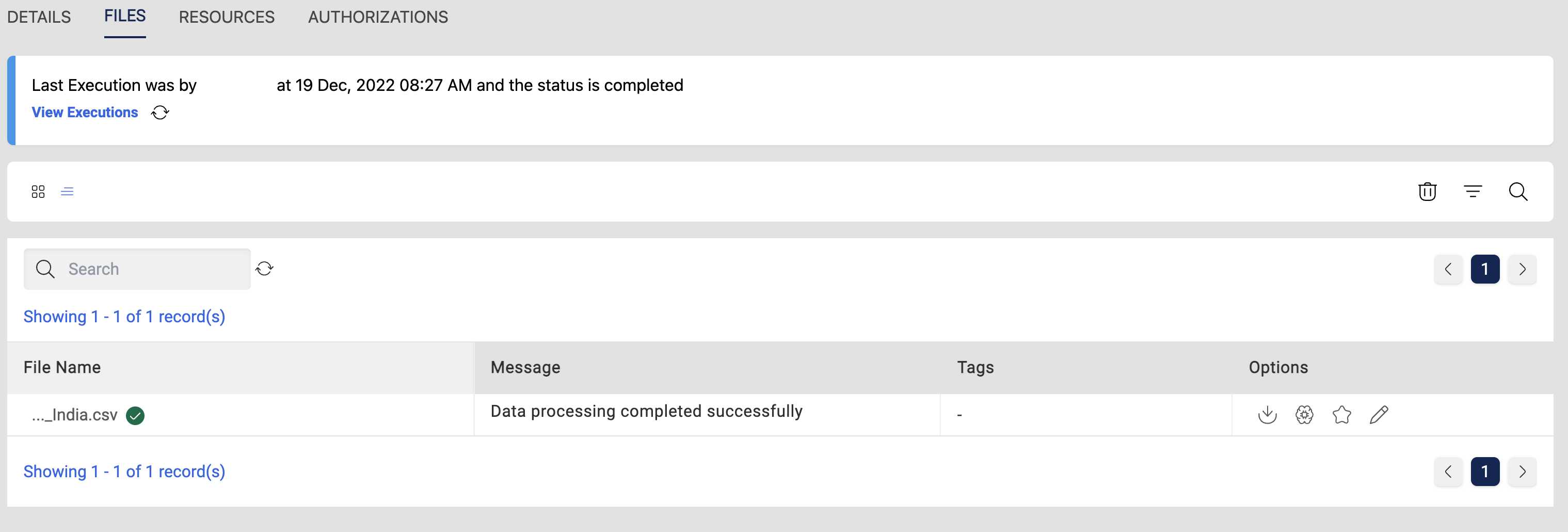
User can also check for history of executions in the View All Executions page for reference.

Reload through API
- User have to write the data files to LZ(Landing Zone) location via ETL or Glue jobs in the Dataset landing location in the below format.
s3://<LZBucket>/<Domain>/<DatasetName>/upload_date=<epoch>/<UserId>/<FileType>/<FileName1>
s3://<LZBucket>/<Domain>/<DatasetName>/upload_date=<epoch>/<UserId>/<FileType>/<FileName2>
s3://<LZBucket>/<Domain>/<DatasetName>/upload_date=<epoch>/<UserId>/<FileType>/<FileName3>
s3://<LZBucket>/<Domain>/<DatasetName>/upload_date=<epoch>/<UserId>/<FileType>/_SUCCESS
- After all the files are uploaded to LZ bucket a trigger file (_SUCCESS) needs to be placed in the same location of the data files to start the dataload.
- As soon as the trigger file is placed in the LZ location, data reload process will start automatically and will be running in the background.
- After all files have been written to the LZ location, user can still go back to UI and can start the data reload as mentioned above.
The _SUCCESS file can be a dummy file not necessarily a real data file as it acts as a trigger and not included in the dlz bucket writing. This file named _SUCCESS should not have file extension.
Delete Unwanted files
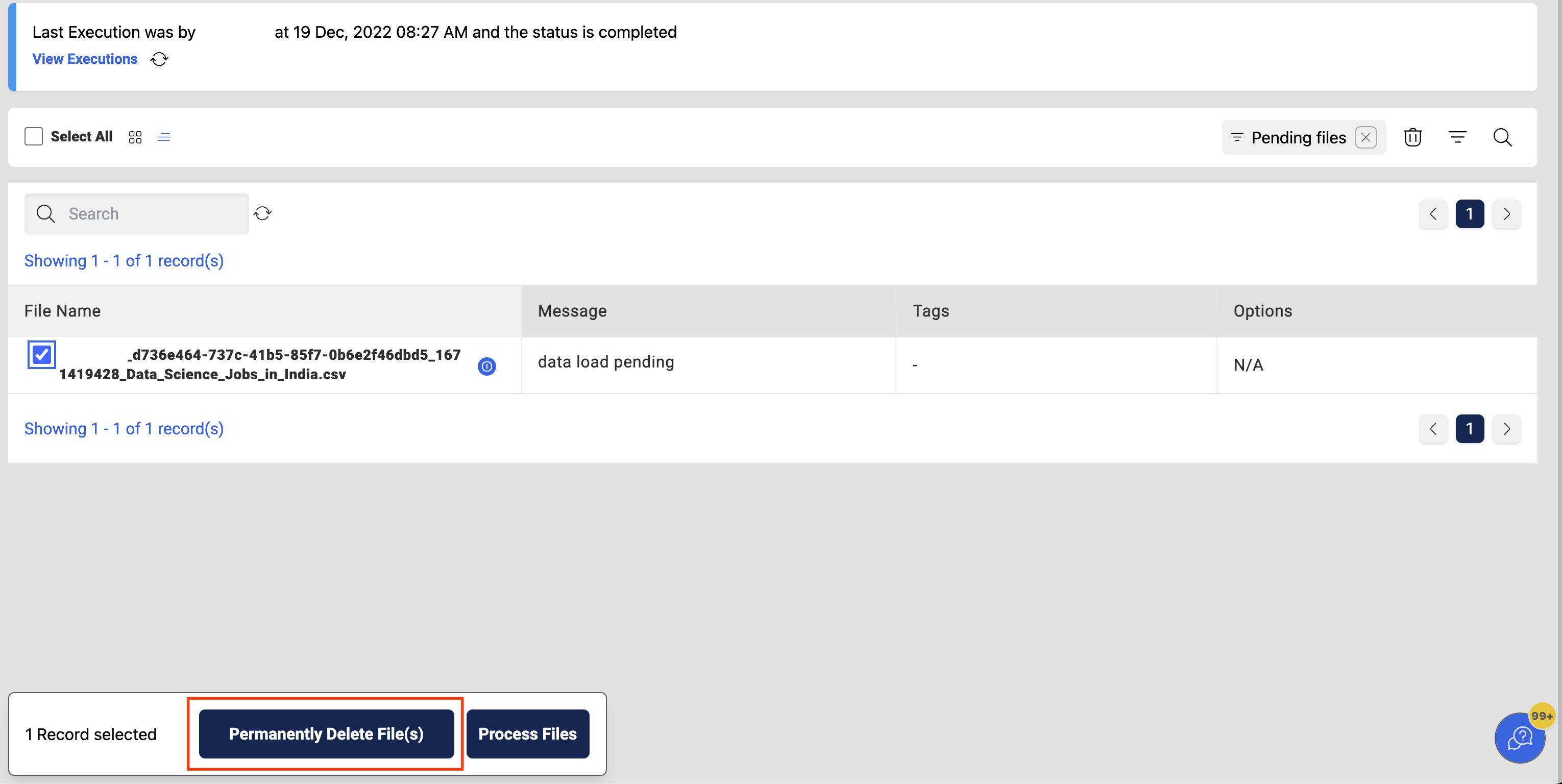
All unwanted files that have been added to the dataset can be deleted from the Pending files page. User have to select all the files that are not required for this dataset and click on Permanently Delete File(s) at the end of the page which deletes the files that are pending status.
Additional Information
- For every successful or failure run an email will be sent to the user with information about the status of the load and the reason for the failure if any.
- If a data reload process is running on the dataset, a concurrent load-run is not allowed and an exception will be raised if the process is started from the UI. In case of API upload an email will be sent to the user.
- Any status of the run will be shown on the executions page along with the reason.
- Datafiles that are added to the dataset will be in pending status and can be processed later in any of the cases above.