
Creating a Parquet dataset
Amorphic supports dataset creation for Parquet on the following Target types,
- Redshift
- S3Athena
- S3
- LakeFormation
Note
- AuroraMySQL isn't currently available for Parquet type dataset
- The Sample file to be uploaded during dataset creation should be of CSV format
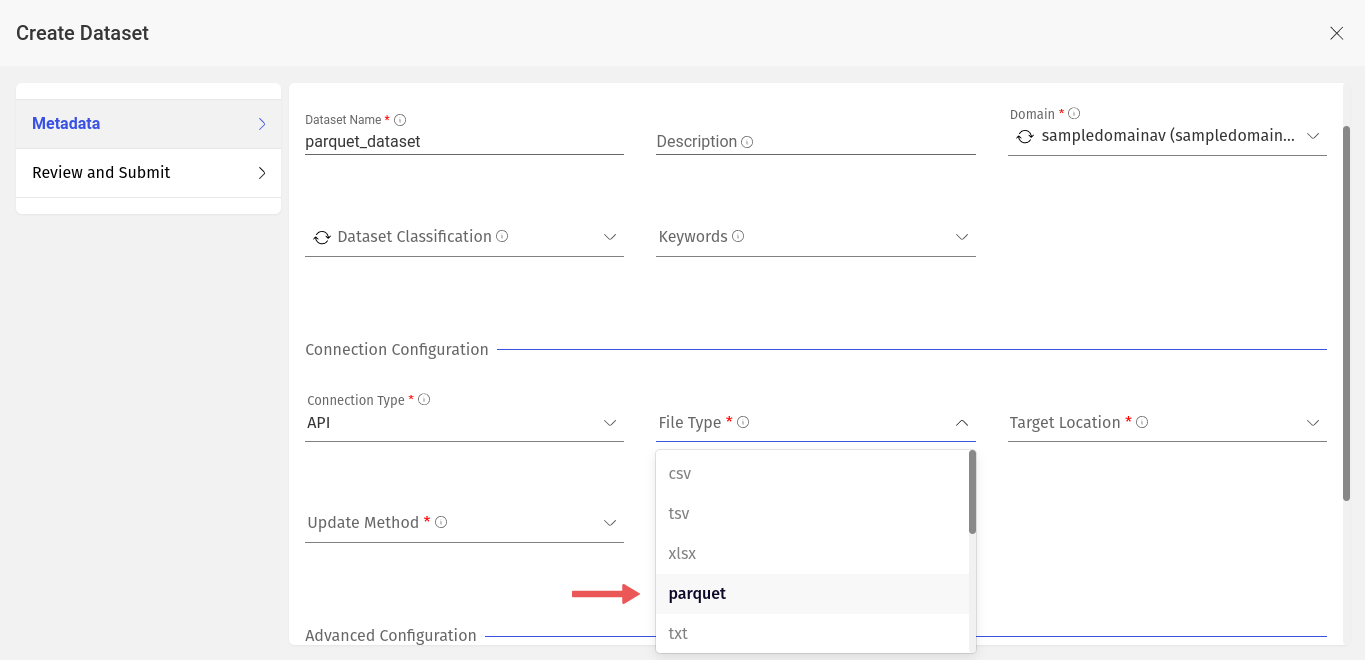
Following are the steps, as shown below, to create a Parquet dataset,
Go to create dataset page, select File Type as Parquet and fill out the appropriate values to remaining fields as per your requirement
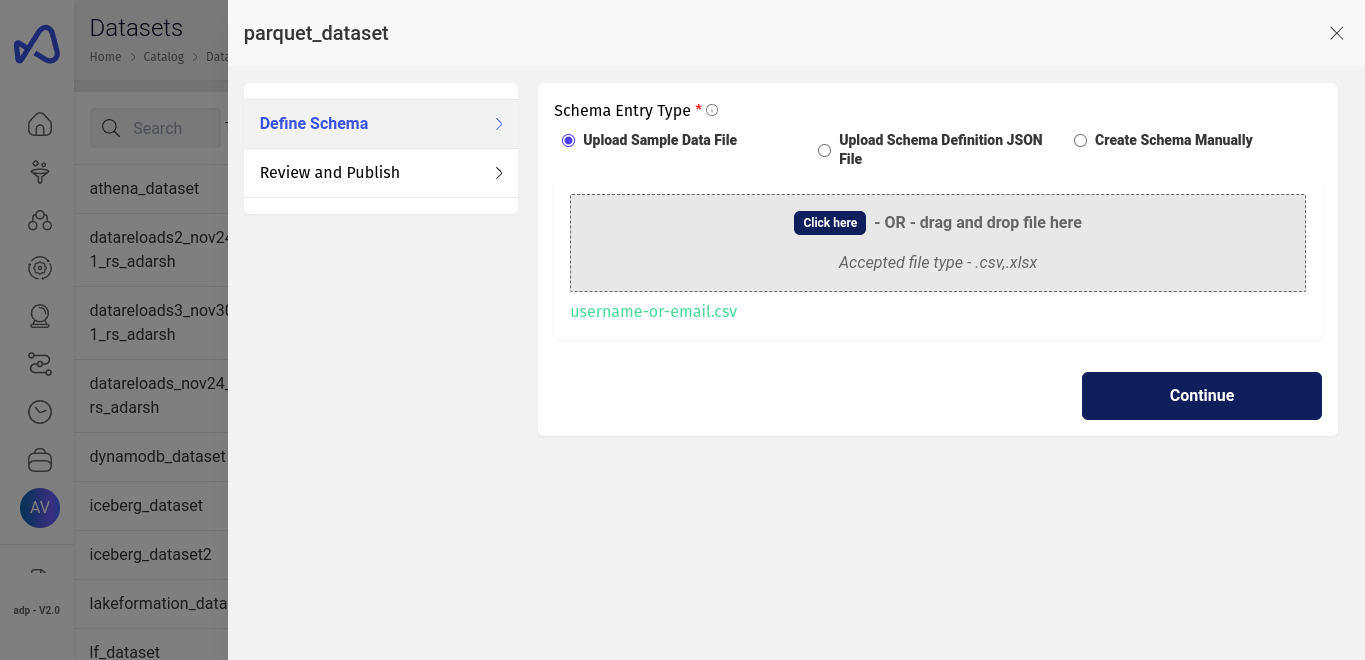
In the second page, Upload Schema, you'd be asked to upload a sample file to extract schema for the dataset. The sample file, should be of CSV file type even for Parquet type datasets.
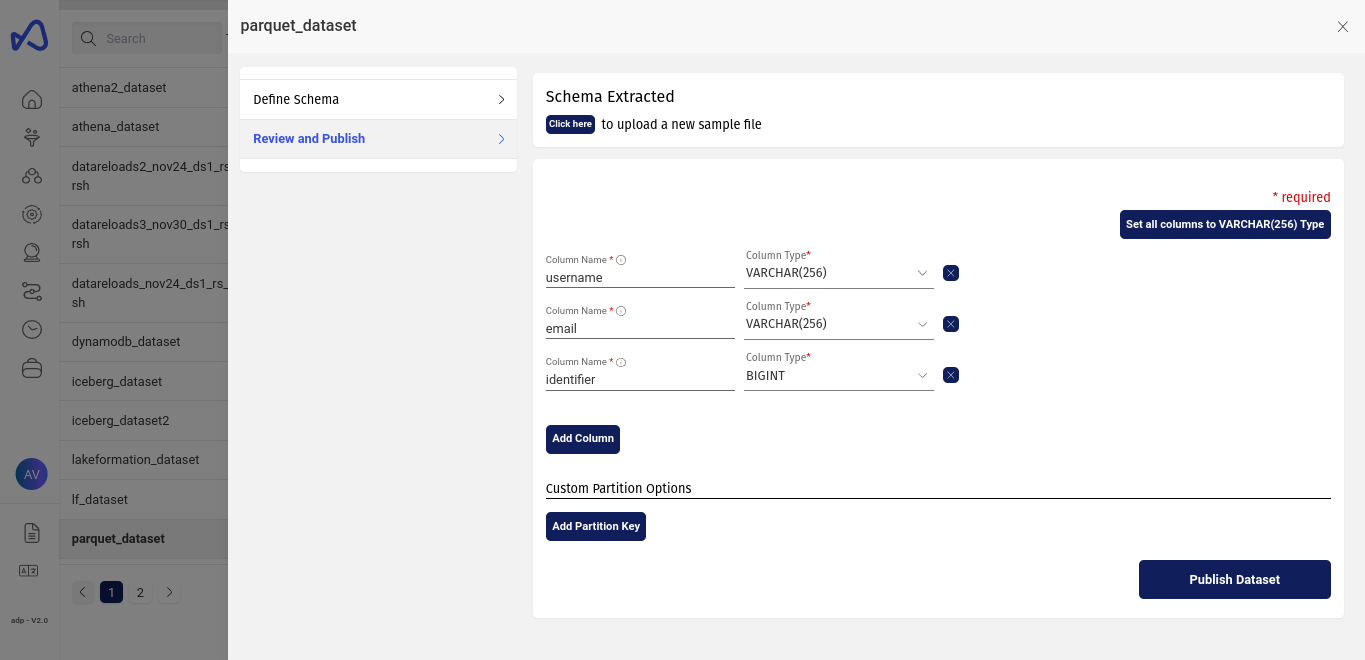
After uploading the sample file, click next to review to the extracted schema and if the schema looks as per requirement, click Publish Dataset