Iceberg Datasets
In Amorphic, User can create Iceberg datasets with S3Athena target location which creates Iceberg table in the backend to store the data.
As of Amorphic 1.14, users can only create Iceberg datasets targeted to S3Athena. If Iceberg becomes compatible with other targets in the future, we will try to incorporate them.
Athena supports read, time travel, write, and DDL queries for Apache Iceberg tables that use the Apache Parquet format for data and the AWS Glue catalog for their metastore.
What is Apache Iceberg?
Apache Iceberg is an open table format for big data analysis. It can manage lots of files as tables and provides modern data lake operations like record-level inserts, updates, deletes, and time travel queries. Iceberg also makes it possible to update the table's schema and partitions, and it's optimized for usage on Amazon S3. Plus, it helps ensure data accuracy when multiple people write at the same time. To learn more, check out the Apache Iceberg Documentation.
What does Amorphic support?
Amorphic Iceberg datasets support following features:
- ACID transactions
- ACID (atomic, consistent, isolated, and durable) transactions protect the integrity of Data Catalog operations such as creating or updating a table. They enable multiple users to concurrently add and delete objects in the Amazon S3 data lake, while also allowing for queries and ML models to return consistent and up-to-date results. Iceberg tables are involved in reads and writes, and use transactions to protect the manifest metadata. AWS services such as Amazon Athena support iceberg tables. To use transactions in AWS Glue ETL jobs, begin a transaction before performing reads/writes, and commit it upon completion. For more info, see Reading from and Writing to the Data Lake Within Transactions.
- Set/Unset Table properties (User can specify attributes like Write compression, Data optimization configuration etc)
- Schema evolution (Add, Drop, Rename, Update (changing data type) columns)
- Hidden-Partitioning
- Time travel queries to specified date and time
- Version travel queries to specified snapshot ID (Table version)
- Queries combining time and version travel
- Iceberg table data can be managed directly on Athena using INSERT, UPDATE, and DELETE queries.
- Optimizing Iceberg tables data by REWRITE DATA compaction action
- Row-level deletes
For more information about Athena supported Iceberg features and limitations, Check Athena Iceberg Documentation
Limitations (Both AWS and Amorphic)
- Supported data types
- Applicable to ONLY 'S3Athena' TargetLocation and 'Parquet' FileType
- Restricted/Non-Applicable Amorphic features for Iceberg datasets
- S3Athena DataValidation
- Skip LZ (Validation) Process
- Malware Detection
- Data Profiling
- Data Cleanup
- Data Metrics collection
- Life Cycle Policy
- No Partition evolution (Changing partitions after table creation)
- Only predefined list of key-value pairs allowed in the table properties for creating or altering Iceberg tables. Check AWS Documentation
- Schema evolution:
- Allowed ONLY a set of update column (data type promotions) actions:
- Change an integer column to a big integer column
- Change a float column to a double
- Increase the precision of a decimal type column
- Reorder columns is not supported
- Allowed ONLY a set of update column (data type promotions) actions:
How to Create Iceberg Datasets?
In Amorphic, you can create Iceberg datasets like Athena datasets by selecting 'S3Athena' as target, 'parquet' as file type, and 'Yes' in 'Iceberg Table' dropdown. Add Iceberg table properties in key-value pairs in 'Iceberg Table Properties' section. Refer to Iceberg documentation for supported table properties.
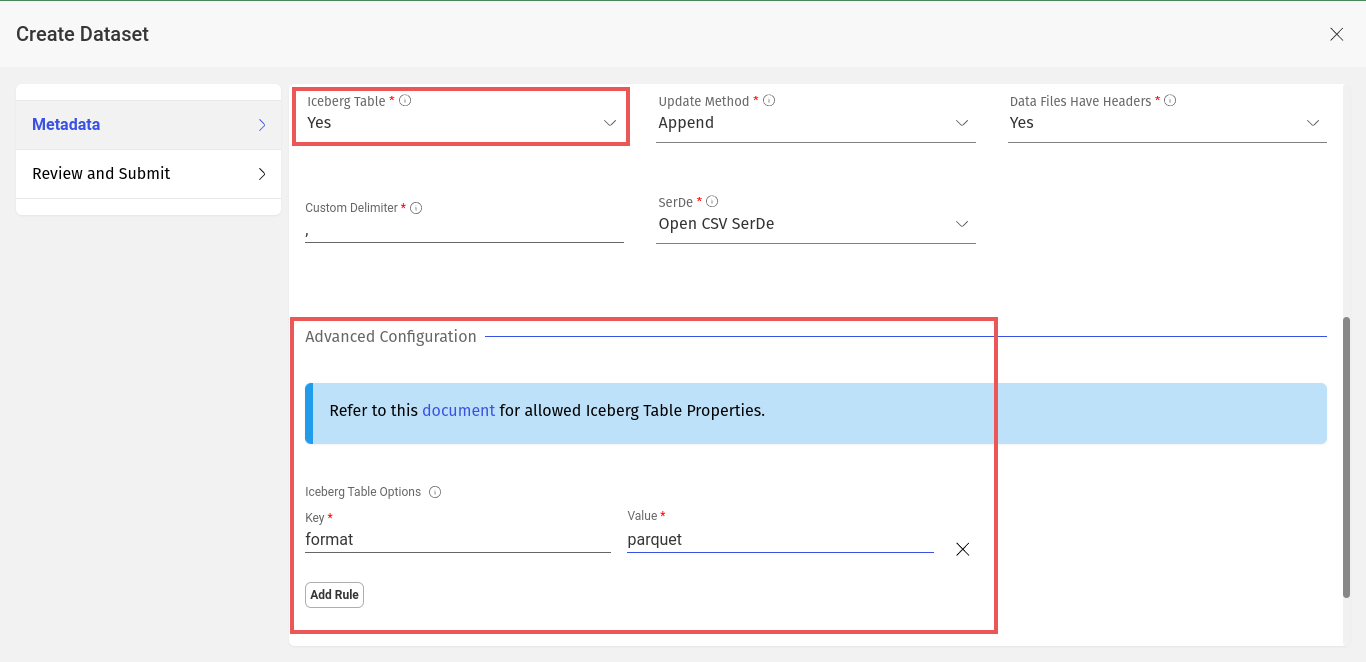
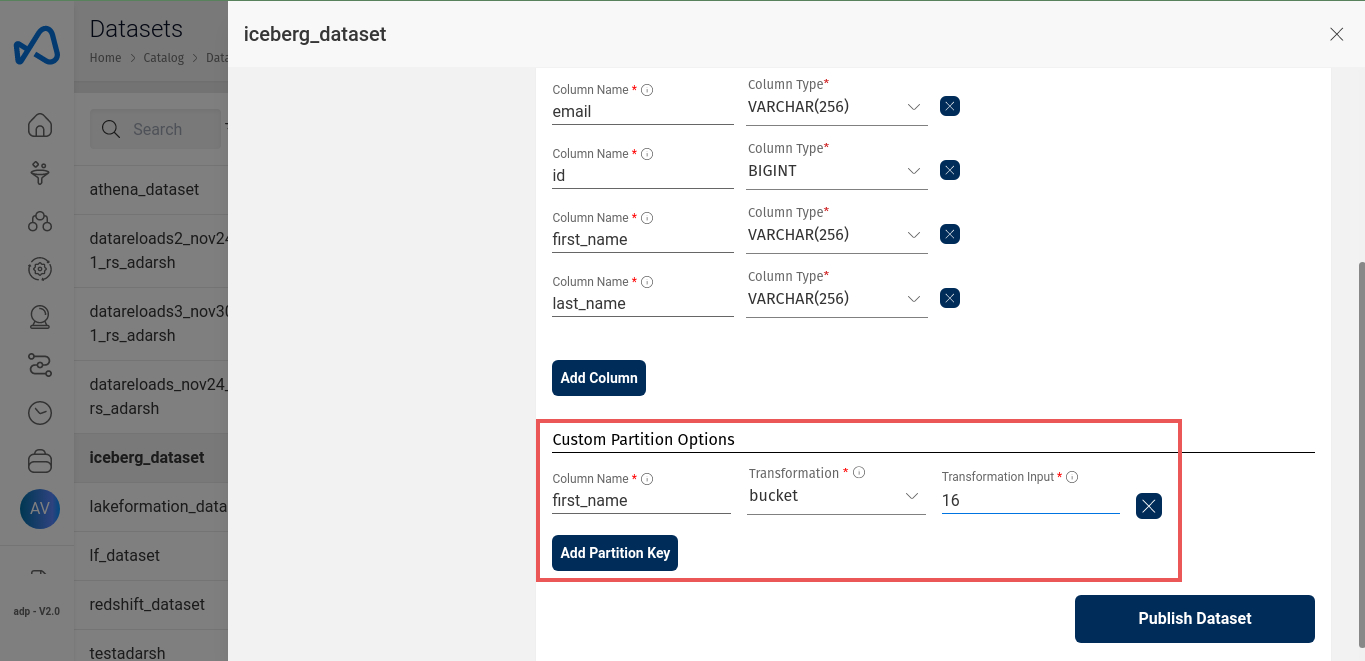
Upon successful registration of Dataset metadata, you can specify partition related information through 'Custom Partition Options' with following attributes:
- Column Name: Partition column name which should be of any column name from schema.
- Transformation: Iceberg (Hidden partitioning) converts column data using partition transform functions. Available functions: year, month, day, hour, bucket, truncate, None (no transformation).
- Transformation Input: If Transformation is either bucket or truncate then additional input should be provided. Input value should be a positive number.
For more information, Check documentation for Iceberg Partitioning.
Load Iceberg Datasets
Uploading data to Iceberg datasets is like Amorphic's "Data Reloads" where files go into a pending state. Select files in the "Pending Files" option in the Files tab, then processing begins in the backend, taking longer than other types of datasets.
Below options will not be available for Iceberg dataset:
- 'Add Tags', 'Delete' and 'Permanent Delete' options when completed files are selected in 'Complete Files' File Status dropdown.
- 'Truncate Dataset', 'Download File', 'Apply ML' and 'View AI/ML Results' buttons/options for completed files in Files tab.
You can delete the pending files from 'File Status' dropdown in Files tab.
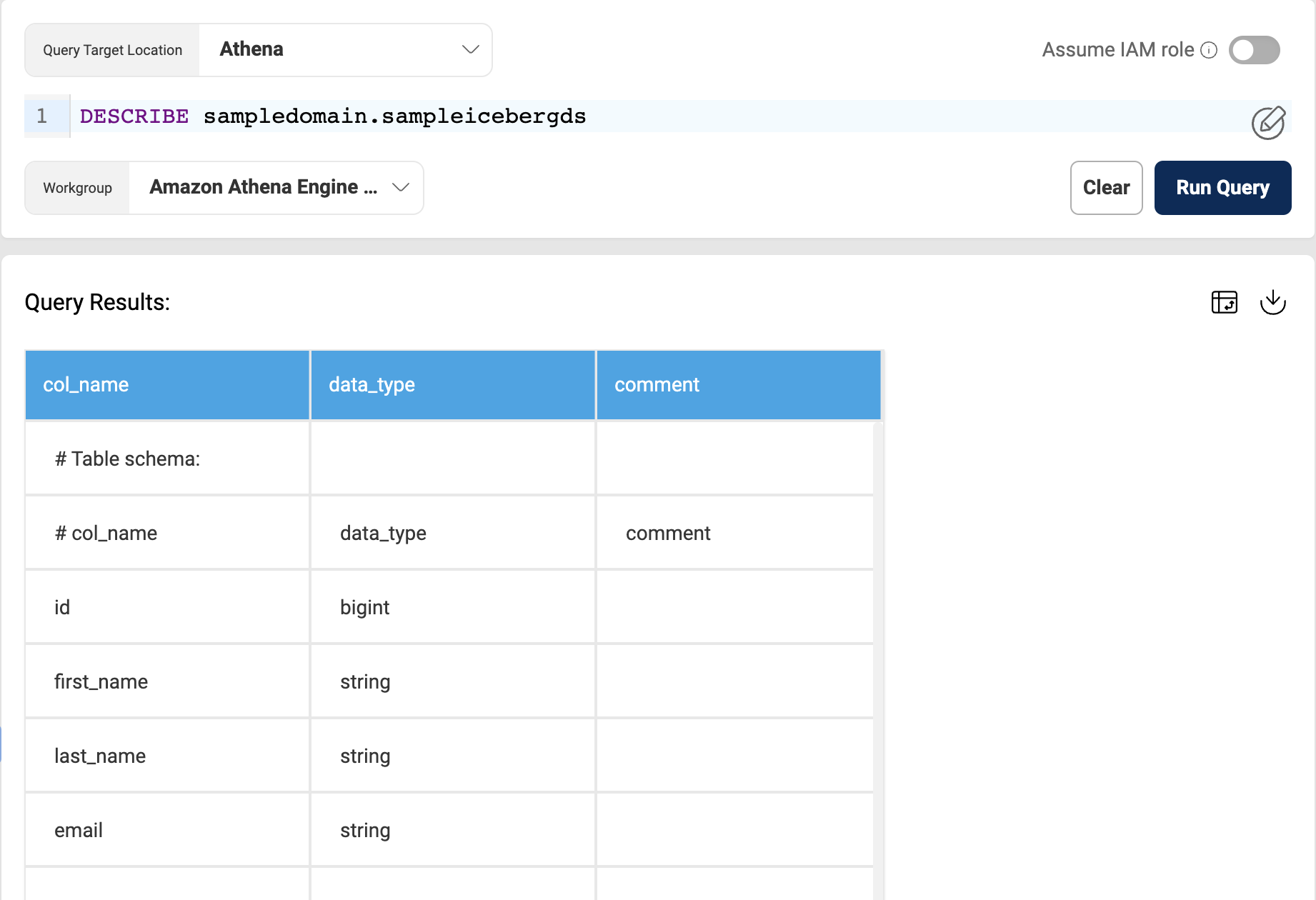
Query Iceberg Datasets
Once the data is loaded into Iceberg datasets, it is available for the user to query and analyze directly from the Amorphic Query Engine feature by selecting the workgroup as AmazonAthenaEngineV3.
Additional commands can be performed for Iceberg datasets for the following actions:
- Iceberg table data can be managed directly on Athena using below commands
- INSERT INTO, UPDATE, DELETE FROM and MERGE INTO
- For more information, Check AWS Documentation
- View Metadata
- DESCRIBE, SHOW TBLPROPERTIES
- SHOW COLUMNS
- For more information, Check AWS Documentation
- Optimize data by REWRITE DATA compaction action
- OPTIMIZE
- For more information, Check AWS Documentation
- Perform snapshot expiration and orphan file removal
- VACUUM
- For more information, Check AWS Documentation
It's better to AVOID the above commands if you do not have knowledge on them as it'll change/delete the data and its metadata based on the specified command.
Below image shows result of "DESCRIBE" table command on an Iceberg dataset: