
Hudi Datasets
In Amorphic, User can create Hudi datasets with Lakeformation target location which creates Hudi table in the backend to store the data.
What is Apache Hudi?
Apache Hudi is an open-source data management platform that makes incremental processing easier. Insert, update, upsert, and delete actions at the record level are handled much more granularly, decreasing overhead. Upsert refers to the capability to add new records to an existing dataset or update existing ones. To learn more, check out the Apache Hudi Documentation.
What does Amorphic support?
Amorphic Hudi datasets support following features:
- ACID transactions
- Apache Hudi brings ACID (atomic, consistent, isolated, and durable) transactional guarantees to a data lake. Hudi ensures atomic writes, by way of publishing commits atomically to a timeline, stamped with an instant time that denotes the time at which the action is deemed to have occurred. Unlike general purpose file version control, Hudi draws clear distinction between writer processes (upserts/deletes), table services (data/metadata) and readers (that execute queries and read data). Hudi provides snapshot isolation between all three types of processes, meaning they all operate on a consistent snapshot of the table.
- Set/Unset Table properties (User can specify attributes like Hudi Write Operation Type)
- To perform Insert, Update, Delete operations on Apache Hudi tables, we need to use frameworks such as Apache Spark or custom ETL processes to acheive the same.
- Supports both table types
- Copy on Write (CoW) - When a record in a CoW dataset is updated, the file containing the record is overwritten with the new values. Better suited for read-intensive tasks on data that changes less frequently.
- Merge on Read (MoR) - When a MoR dataset is updated, Hudi just writes the row for the altered record. Better suited to workloads that require a lot of writing or changes but have few readings.
- Supported file types - Csv, Json, Parquet
The table below displays the possible Hudi query types supported by Amorphic for each table type.
| Table type | Amorphic supported Hudi query types |
|---|---|
| Copy On Write | Snapshot - Retrieves the most recent snapshot of the table as of a specific commit |
| Merge On Read | Read-Optimized - Displays the most recent data compacted |
For more information about Athena supported Hudi features and limitations, Check Athena Hudi Documentation
Limitations (Both AWS and Amorphic)
Applicable to ONLY 'Lakeformation' TargetLocation
Restricted/Non-Applicable Amorphic features for Hudi datasets
- DataValidation
- Skip LZ (Validation) Process
- Malware Detection
- Data Profiling
- Data Cleanup
- Data Metrics collection
- Life Cycle Policy
Currently, No Schema/ Partition evolution is supported by amorphic for Hudi Datasets.
Only predefined list of key-value pairs allowed in the table properties for creating or altering Hudi tables.
Property name values hoodie.datasource.write.operation upsert, insert Currently, incremental queries are not supported
Currently, CTAS or INSERT INTO on Hudi data are not supported
Using MSCK REPAIR TABLE on Hudi tables is not supported.
Athena itself doesn't provide native support for performing insert, update, delete queries directly on Apache Hudi tables.
TBAC for Hudi Datasets is not supported by Amorphic at the moment.
For more limitation, Check Athena Hudi Documentation
How to Create Hudi Datasets?
In Amorphic, you can create Hudi datasets like lakeformation datasets by selecting Lakeformation as target and file types from any of the following (csv, json, parquet), and Yes in 'Hudi Table' dropdown. Update method can be either 'append' (will append data to the existing dataset) or 'overwrite' (will rewrite the new data on the existing dataset). Add Hudi table properties in key-value pairs in 'Hudi Table Properties' section.
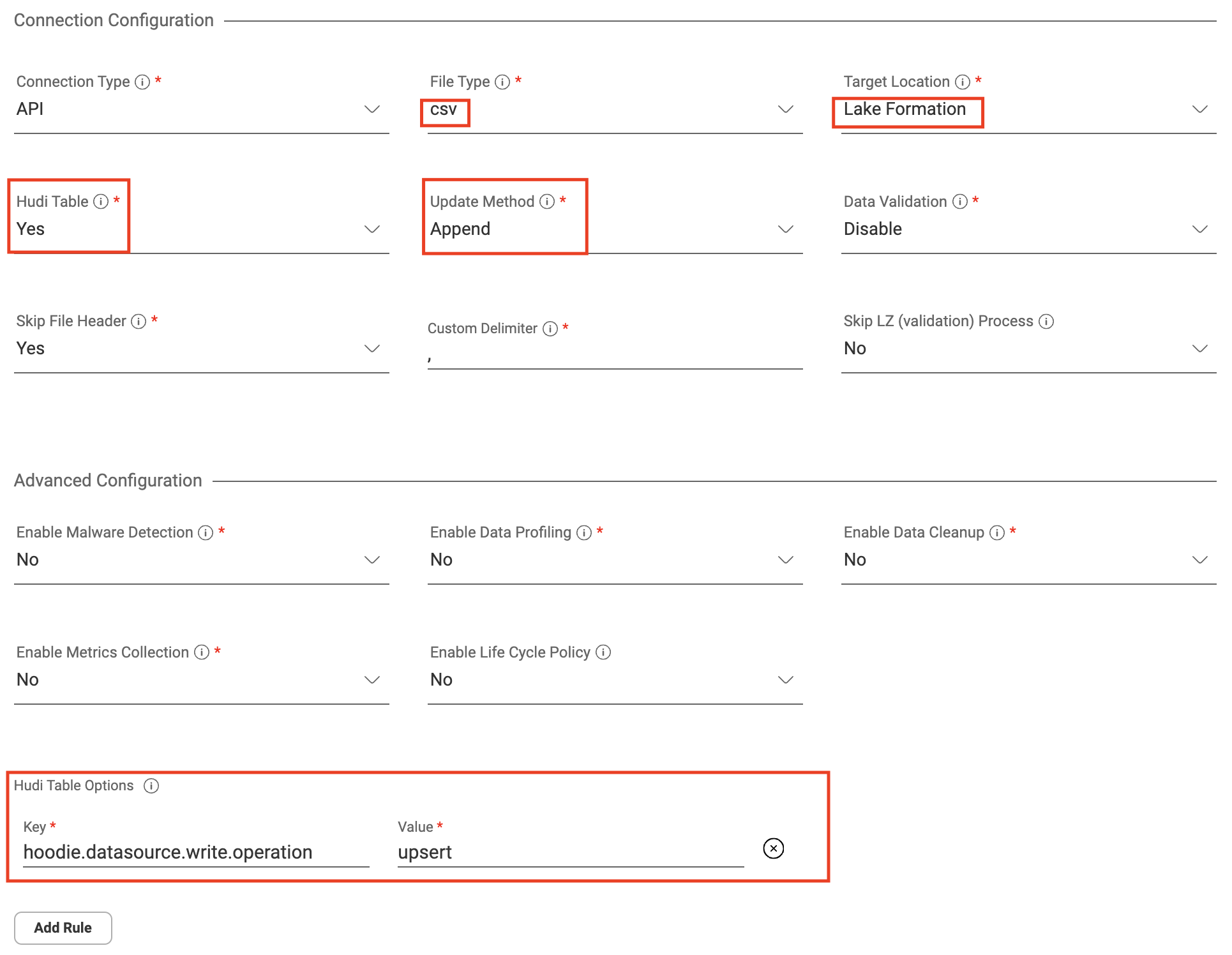
Upon successful registration of Dataset metadata, you can specify hudi related information with following attributes:
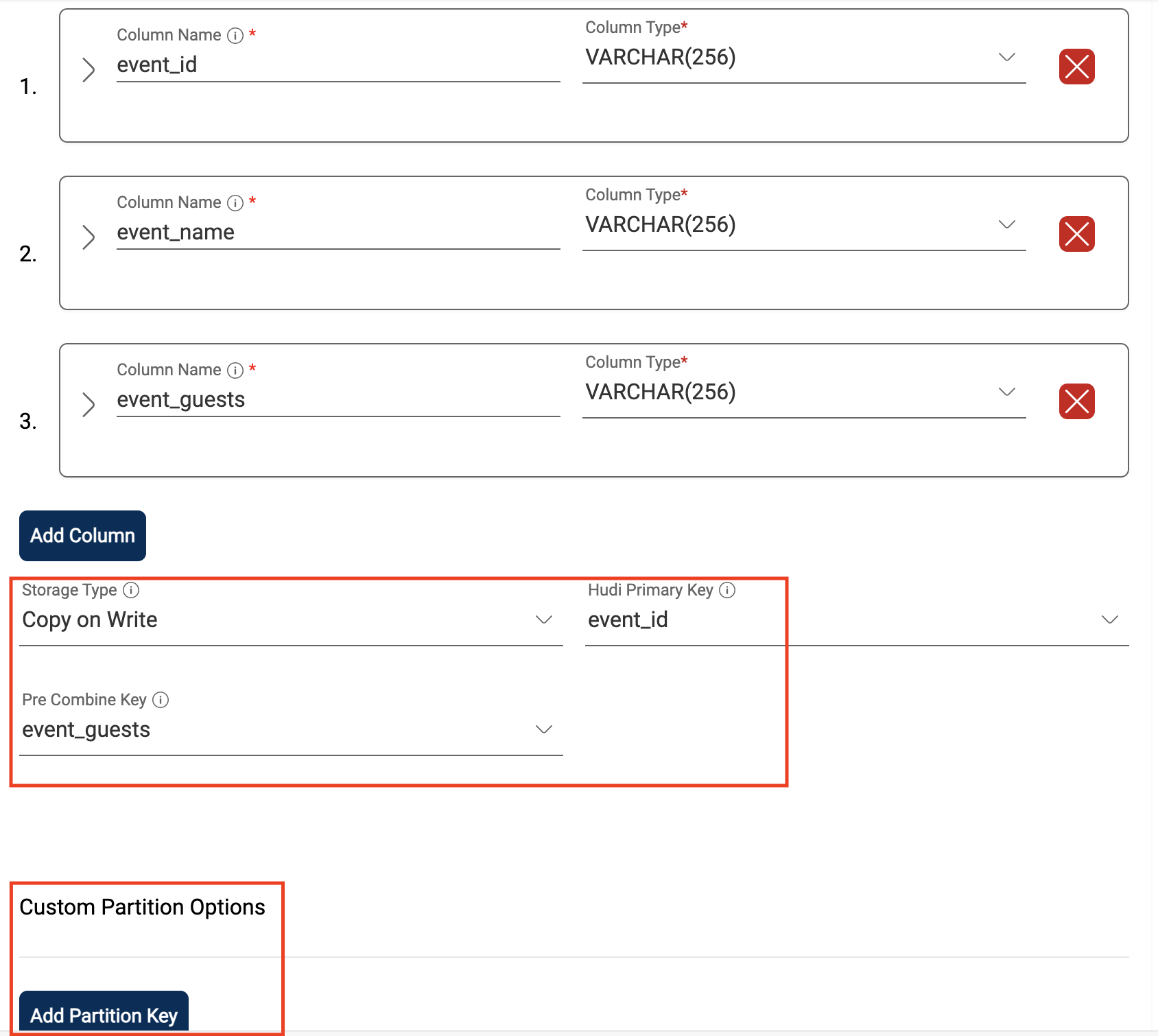
Storage Type: Hudi Storage type which should be either Copy on Write or Merge on Read.
Hudi Primary Key: Hudi primary key which should be of any column name from schema.
Pre Combine Key: Hudi precombine key which should be of any column name from schema.
You can specify partition related information through 'Custom Partition Options' with below attribute:
Column Name: Partition column name which should be of any column name from schema.
Load Hudi Datasets
Uploading data to Hudi datasets is like Amorphic's "Data Reloads" where files go into a pending state. Select files in the "Pending Files" option in the Files tab, then processing begins in the backend, taking longer than other types of datasets.
Below options will not be available for Hudi dataset:
- 'Add Tags', 'Delete' and 'Permanent Delete' options when completed files are selected in 'Complete Files' File Status dropdown.
- 'Truncate Dataset', 'Download File', 'Apply ML' and 'View AI/ML Results' buttons/options for completed files in Files tab.
You can delete the pending files from 'File Status' dropdown in Files tab.
Query Hudi Datasets
Once the data is loaded into Hudi datasets, it is available for the user to query and analyze directly from the Amorphic Query Engine feature.
Additional commands can be performed for Hudi datasets for the following actions:
- View Metadata
- DESCRIBE, SHOW TBLPROPERTIES
- SHOW COLUMNS
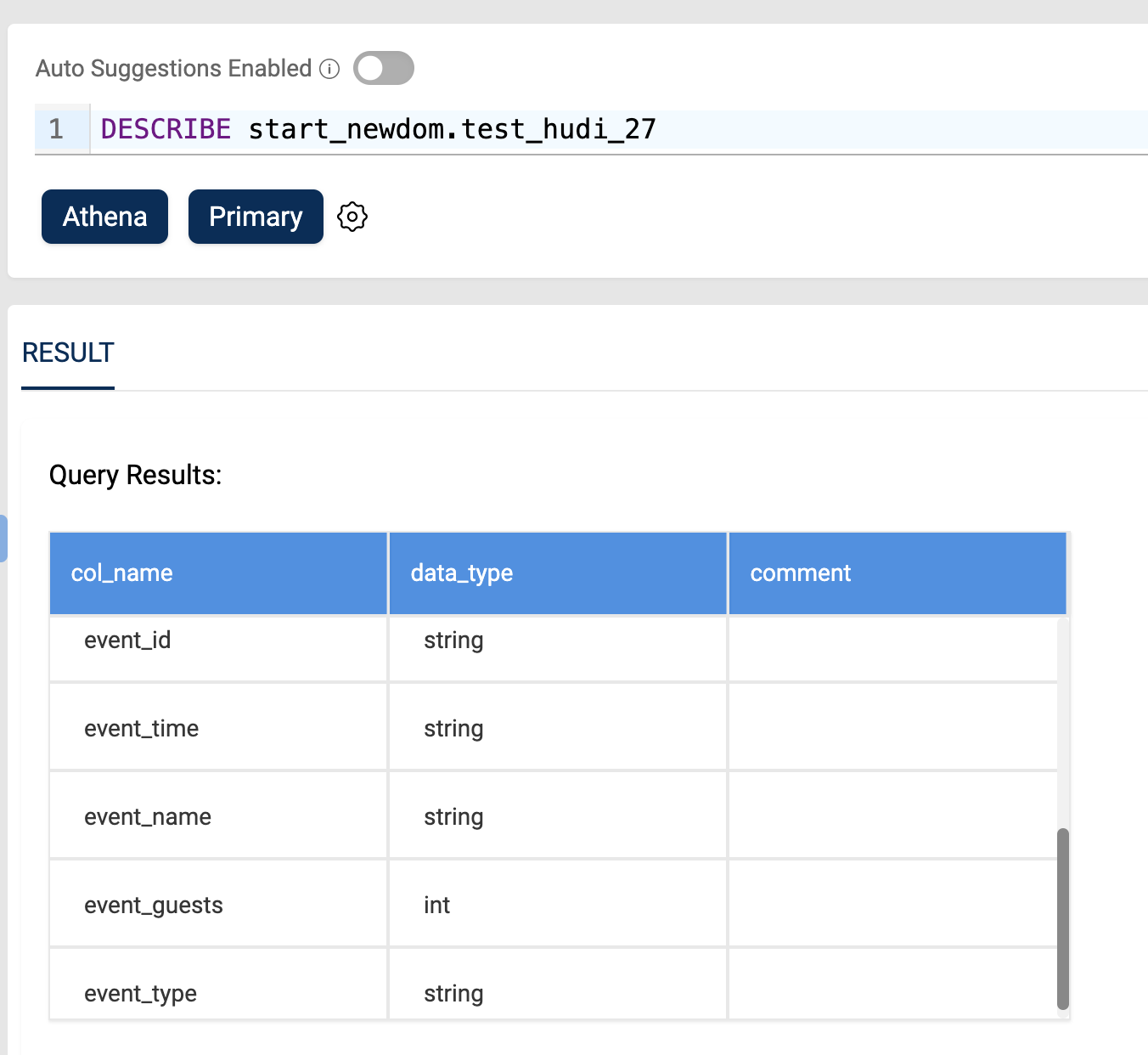
Below image shows result of "DESCRIBE" table command on an Hudi dataset:
On AWS Hudi MoR
By default, for all datasets created with MoR storage types have two internal tables created by backend hudi process. One is
table_name_roand the other istable_name_rttable_name_rois the read optimized view of the table and shows only compacted datatable_name_rtis the real time view of the table and shows all the latest data
Compaction
- For non-paritioned ones, all data exposed to read optimized queries are compacted by default.
- For paritioned ones, we have to do manual compaction for every partition by running the below command.
ALTER TABLE database_name.table_name ADD PARTITION (partition_key = partition_value) LOCATION 'location_path'
- By default hudi tables are created under DLZ bucket in amorphic account
- Currently
table_name_roandtable_name_rtboth shows the latest data (checking with aws on the same) and to get only the compacted data, query thetable_namealone - In the manual compaction process, location_path should be of the following format:
<DLZ_bucket>/<Domain>/<DatasetName>/<partitions_key=partition_value>/ - Inorder to access
table_name_roandtable_name_rtthrough query engine, it is mandatory to assume user IAM role
Resource Sync Hudi datasets to Amorphic from Cross Account/ Cross Region
Prerequisites that are needed as part of Hudi resource syncing from other account. These steps needs to te performed on aws console directly.
From Source Account A,
- Go to LakeFormation, Select the appropriate DB and table and revoke IAM allowed principals inorder to grant access to other account. If already revoked, skip this action.
- Then, Resource needs to be grant permissions (min Select) to Account B by selecting the appropriate DB and table
- Need to provide appropriate permissions in kms to other account (esp for admin, resource sync roles) in appropriate gluecatalog key if glue catalog is encrypted
From Target Account B,
- If organizational accounts are different, go to RAM (Resource Access Manager), and accept the resource shared from Source Account A. If account is already accepted, skip the action.
- Go to LakeFormation in the same region as Account-A and choose the appropriate resource, select Actions -> Grant, Provide permissions and grantable permissions (both min
Select) to resource sync lambda role.- If we are providing access to tables, we need to choose database as
defaultwhile providing permissions (since shared tables will come under default db) - If default db does not exist, kindly create the same and try providing access now.
- If we are providing access to tables, we need to choose database as
- Go to LakeFormation in the preferred region of Account-B, Click on Create Resouce Link option
- Provide the table name here by choosing appropriate db (in which database you need to place this destined table)
- Choose the appropriate source region (region of Account-A) and choose the source table and db name and provide grant
Need to update necessary description as shown below (in Glue/ Lakeformation), inorder to sync the resource back to Amorphic.
Request Description: { source: awsconsole, owner: owner-name, additionaloptions: { framework_type: hudi, source_account_region: region-name } }If we run resource sync lambda post this, then resources will be synchronized and can be accessed from Amorphic UI.
Then again go to Source Account A,
- Need to provide appropriate permissions in kms to other account for below hudi role in appropriate gluecatalog kms key if glue catalog is encrypted.
Hudi IAM role: adp-custom-CORSforHudiDatasets-Role
Post succesful resource syncing, we can see the resource sync-ed hudi dataset in Amorphic UI and can ONLY do read operation using athena query engine. We can also create a view on top of that independent resource sync-ed hudi dataset.
- As part of this hudi cross account/ region resource sync, new hudi iam role will be created and the required policies will be attached related to it.
- Irrespective of the permissions that are granted to target account, we are limiting permissions to
Read-onlyin the target account. - While updating the Description,
source_account_regioncan be skipped if source and destination account regions are same. - We can only update the new hudi iam role in source account after running resource sync lambda.
- This new hudi role will be assumed by datasets, views, athena queries inorder to access hudi data from source account.
- We cannot create view on top of multiple datasets where one of the dataset is cross account/region resource sync-ed hudi dataset.
- We don't need to worry about source s3 bucket encryption/ bucket policy as granting permissions through Lakeformation overrides those necessary permissions.
- If the Hudi MoR table has been resource sync-ed, then we cannot access those internal tables (
table_name_roandtable_name_rt) from target account. If we want to access those tables, then we want to explicitly share it like we do for other tables.