
Lakeformation Datasets
Amorphic Dataset portal helps you create structured, semi-structured and unstructured Datasets. These Datasets can be used as a single source of truth across the different departments of an organization. Amorphic Datasets helps in providing complete data lake visibility of data.
Amorphic Dataset page consists of options to List or Create a new Dataset. Datasets are available to select in the Amorphic Dataset for listing purpose. You can sort through the Dataset using the Domain filters, Create new Datasets or View Dataset details.
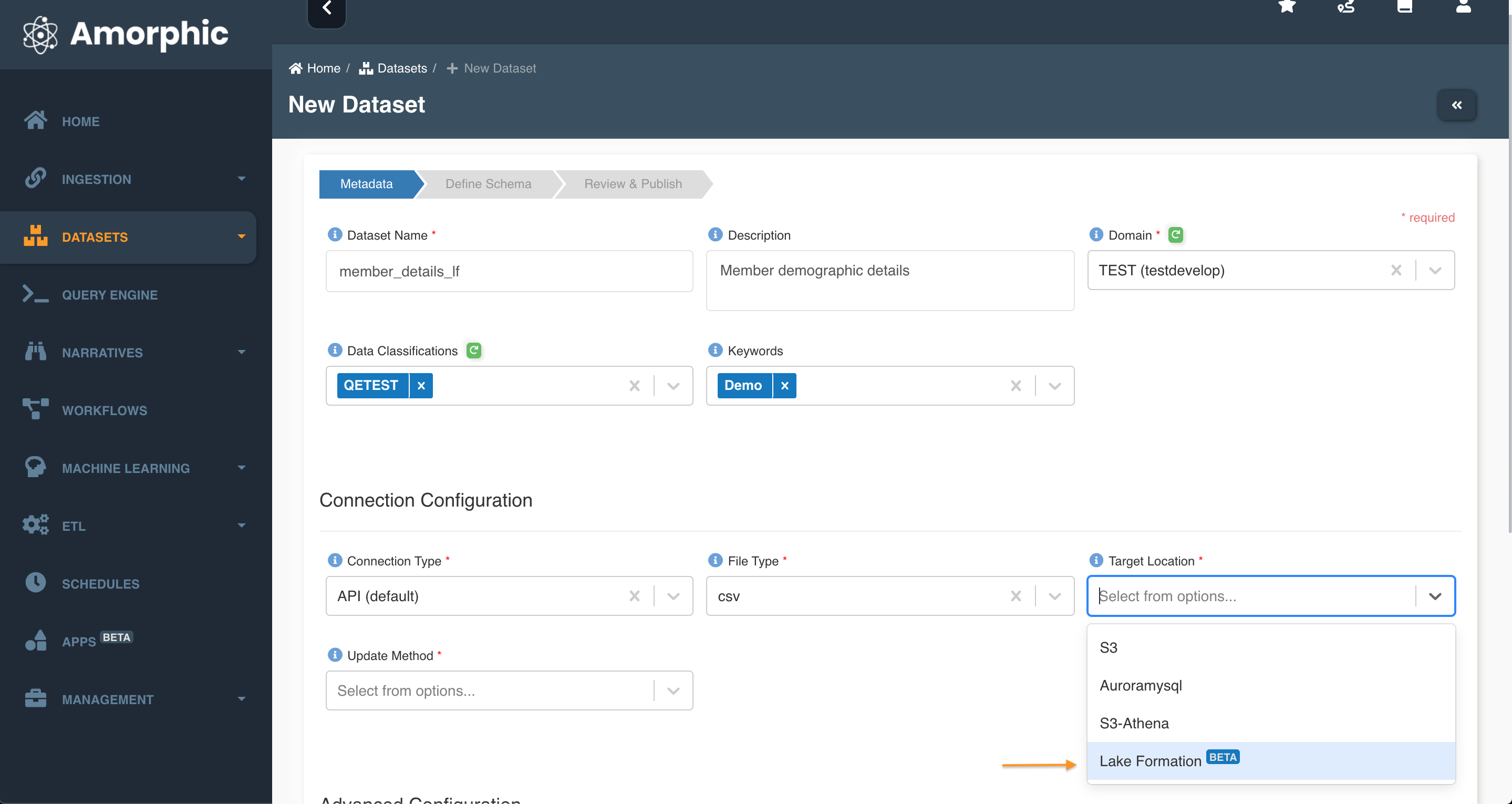
This page explains usage of datasets with target location as Lakeformation(Beta). Amorphic provides user ability to store csv/tsv/xlsx files in s3 without the overhead of maintaining a data warehousing solution for cost effectiveness. Lakeformation can be considered as an extension of S3-Athena datasets with an additional layer of security.
With Lakeformation datasets as the target location, we provide an option of performing a partial data validation on the files uploaded. By default, Data Validation is enabled for lakeformation target location. It can be enabled/disabled at any point of time. Each file is sampled/read partially and every column is validated against the schema which was uploaded to the dataset while registering. This helps the user to quickly detect and perform data correction on corrupt or invalid data files but it takes few extra seconds per file to validate and there will be additional charge per file. As of now, Users can register structured data i.e csv,tsv,xlsx and parquet files and has facility to validate data types such as Strings/Varchar, Integers, Double, Boolean, Date and Timestamp. For accommodating complex data structures we recommend enclosing them in quote chars and register the column schema as String/Varchar once loaded user can perform ETL atop of the data and cast them appropriately.
The CSV Parser/SerDe recommended by AWS Athena has the following limitations:
- Does not support embedded line breaks in CSV files.
- Does not support empty fields in columns defined as a numeric data type.
As per the AWS Documentation one work around to achieve this is to import them as string columns and create views on top of it by casting them to the required data types.
Create Lakeformation Datasets
You can create new Datasets with a wide range of Target locations. This section describes using Lakeformation as target location for the datasets. Currently only structured data with file formats CSV/TSV/XLSX/Parquet. The following animation shows a detail workflow of creating datasets with Lakeformation as target.
Load Lakeformation Datasets
Loading of Lakeformation datasets is same as S3-Athena datasets. please refer to Athena Datasets for more detail.
Fine grained permissions with Lakeformation Datasets
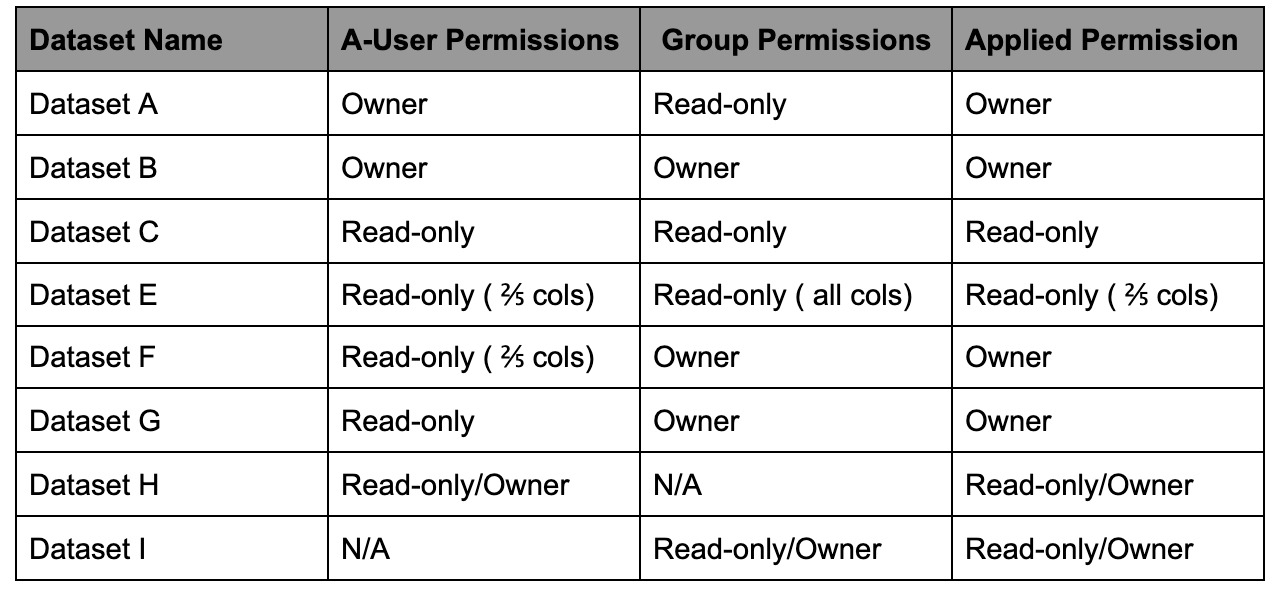
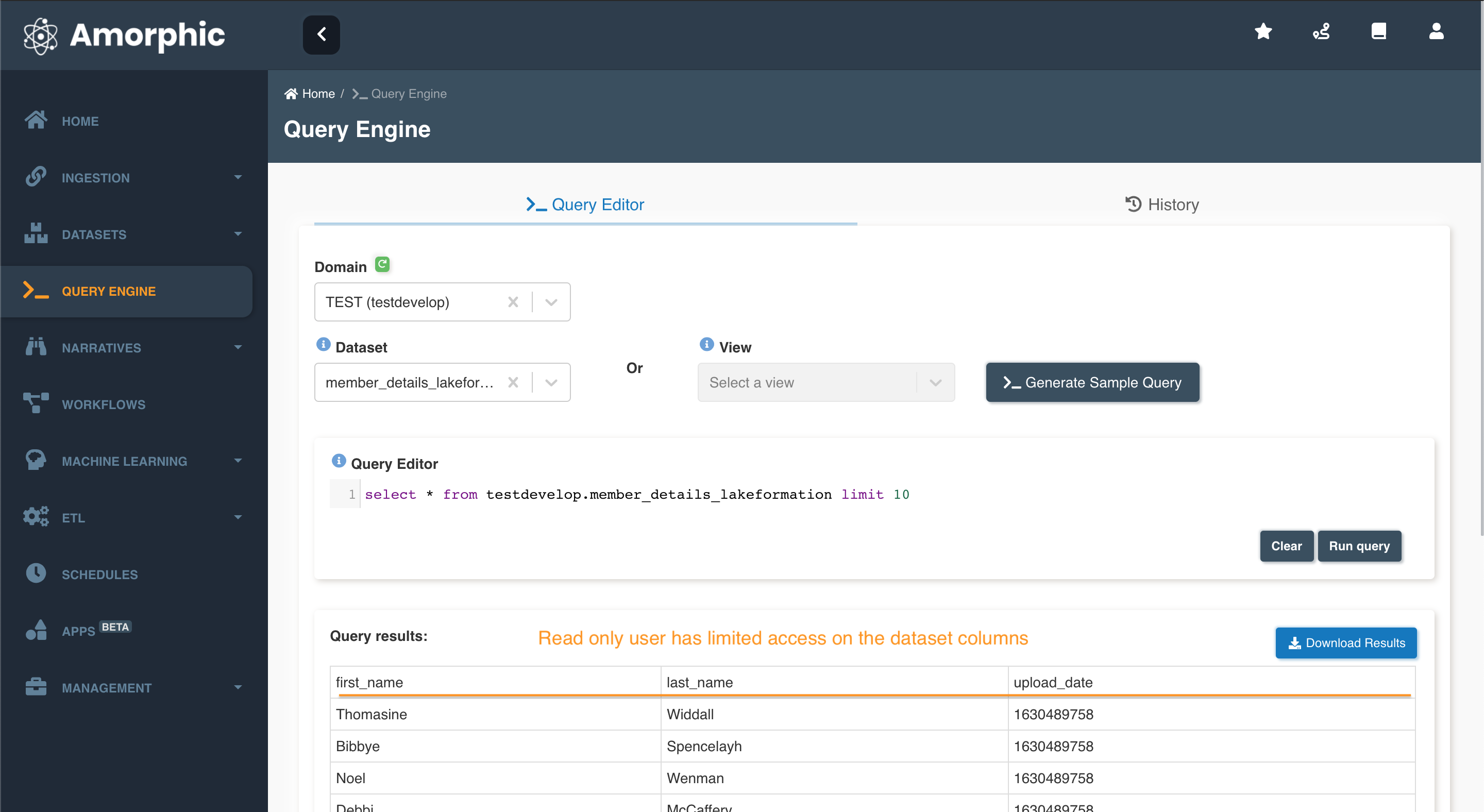
Lakeformation datasets provides an additional layer of security for the data stored. Currently In Amorphic, we provide a two level access control classifying users as Owners/Read-only. With Lakeformation dataset user can enable fine grained access control on the columns. Owners of the datasets are provided with all column access by default and cannot be modified. Fine grained access control is only applied to Authorized read-only members of the dataset. Owner's of the dataset will have the capability of picking individual user and choose what columns can the read-only user can access.
Please find the list of examples on how user permissions are applied based on Authorized Users and Groups
This feature is currently in Beta testing and comes with certain limitations. Please go through the Limitations section for more details.
Below picture shows how to apply fine grained permissions on LF dataset:

read-only members of a lakeformation dataset can only see the columns in dataset schema that the member has permissions for.
Query Datasets
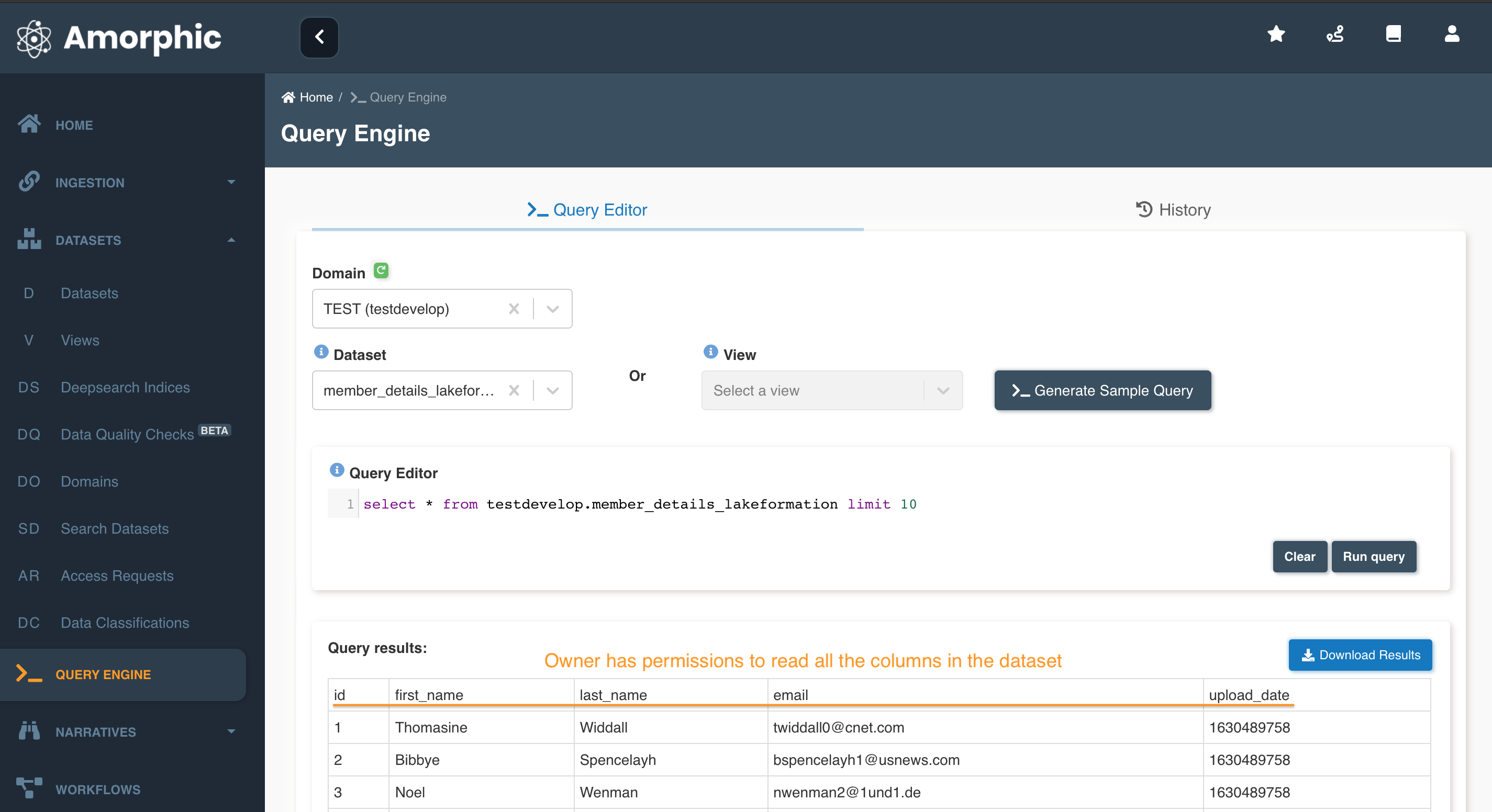
Once we finish loaded data into the datasets, the data is readily available for the User to query and analyze the data directly from the Run Query tab. The following animation shows how can a user run a sample query atop of Datasets.
If user is owner of the dataset then results will be displayed like below:
If user have read-only fine grain permissions on the dataset then results with only allowed columns will be displayed like below:
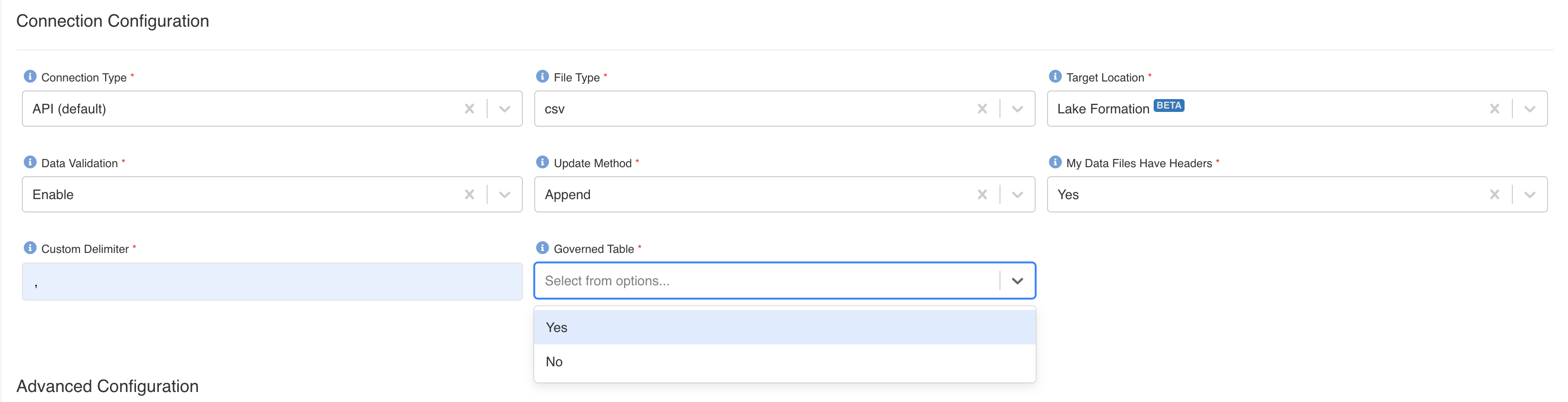
Create Lakeformation Governed Datasets
Same as lakeformation dataset, you can create governed datasets by selecting 'Yes' in newly added 'Governed Table' dropdown.
 The governed datasets support following features:
The governed datasets support following features:
ACID transactions
- ACID (atomic, consistent, isolated, and durable) transactions protect the integrity of Data Catalog operations such as creating or updating a table. They also enable multiple users to concurrently and reliably add and delete objects in the Amazon S3 data lake, while still allowing other users to simultaneously run analytical queries and machine learning (ML) models on the same datasets that return consistent and up-to-date results. When governed tables are involved in reads from or writes to the data lake on Amazon S3, those operations occur within a transaction. Transactions protect the integrity of governed table metadata, including the manifest—the metadata that defines the Amazon S3 objects in the table's underlying data. Integrated AWS services such as Amazon Athena support governed tables to provide consistent reads in queries. To use transactions in your AWS Glue ETL jobs, you begin a transaction before you perform any reads from or writes to the data lake, and you commit the transaction upon completion. For more information about transactions, see Reading from and Writing to the Data Lake Within Transactions.
Automatic data compaction
- For better performance by ETL jobs and analytics services such as Athena, Lake Formation automatically compacts the small Amazon S3 objects of governed tables into larger objects. Compaction is enabled for governed tables by default.
Time-travel queries
Your queries against governed tables in query engine can include a timestamp to indicate that you want to discover the state of the data at a particular date and time. To submit a time-travel query in query engine, use the syntax FOR SYSTEM_TIME AS OF timestamp or FOR SYSTEM_VERSION AS OF version.
select * from lfdomain.lfdomain_test002 FOR SYSTEM_TIME AS OF TIMESTAMP '2022-02-02 08:15:00 UTC'
Limitations
- Fine grained permissions are not supported in Groups. if a user has fine grained permissions applied at a authorized user level and has read-only permissions through the group, Amorphic applies the narrowed down permissions i.e the fine grained row and column permissions set at the authorized user level. Please refer to the how are permissions applied section above.
- ETL and ML services in Amorphic such as Machine learning notebooks, ETL notebooks and Jobs don't support attaching read-only lakeformation datasets to the user.
- Views:
- View permissions needs to be aligned with Dataset permissions i.e Owner of the view needs to provide the dataset access of the underlying lakeformation dataset before granting the view access.
- When the owner of the Lakeformation dataset updates the access control using Authorized users or groups, Querying the view
fails with a message saying
view is stale; it must be re-created. Owner of the view needs to either use theCREATE OR REPLACEstatement to recreate the view or delete and re-create the view with necessary user permissions. Please check AWS Documentation for more details - Users are not allowed to create views on top of governed datasets.
- DMS tasks doesn't support loading of data to Lakeformation target datasets.
- Currently we can register only 500 (maximum limit) Lakeformation datasets with AWS due to characters limitation on IAM policy. If user getting this error message
DS-1061 - Failed to register dataset in the lakeformation catalog, error message : Unable to register the following path: s3://...this can be due to the limit issue, for a workaround you can remove the unnessary Lakeformation datasets from Amorphic and try again to publish new Lakeformation dataset. - Regarding more limitations on lakeformation governed datasets please refer Governed Table restrictions